| 论文英文名字 | Defending against Backdoors in Federated Learning with Robust Learning Rate |
|---|---|
| 论文中文名字 | 以鲁棒的学习率防御联邦学习中的后门 |
| 作者 | Mustafa Safa Özdayi, Murat Kantarcioglu, Yulia R. Gel |
| 来源 | 35th AAAI 2021: Virtual Event |
| 年份 | 2021 年 5 月 18 日 |
| 作者动机 | 防御后门攻击 |
| 阅读动机 | |
| 创新点 | 根据代理更新的符号信息,仔细调整聚合服务器的每个维度和每轮的学习率。 |
内容总结
聚合方法
(1) FedAvg
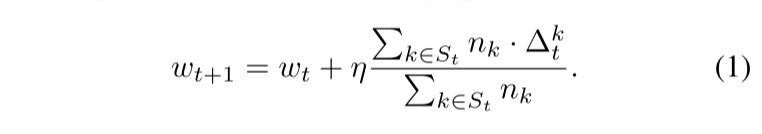
(2) (Sun et al. 2019) 表明,当 FedAvg 与 (Geyer, Klein, and Nabi 2017) 中介绍的权重裁剪和噪声添加相结合时,可以使 FedAvg 在某些设置中对后门攻击具有鲁棒性。
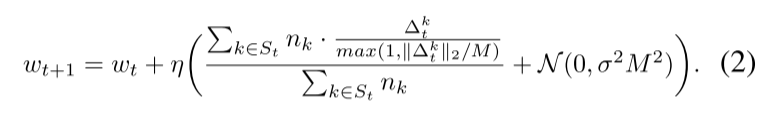
(3) (Fung, Yoon, and Beschastnikh 2020) 试图通过引入每个客户端的学习率而不是在服务器端使用单一的学习率来使 FL 变得健壮。
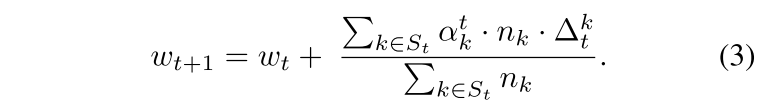
(4) 在 (Bernstein et al. 2018) 中,作者开发了一种通信高效的分布式 SGD 协议,其中代理只通信其梯度的符号。在这种情况下,服务器聚合接收到的符号并将聚合的符号返回给使用它在本地更新其模型的代理。 我们将他们的聚合技术称为符号聚合。
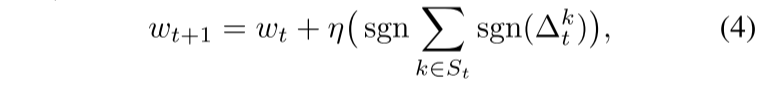
鲁棒的学习率(RLR)
- 后门任务和主任务
$\Delta_{adv}$ 和 $\Delta_{hon}$ 分别是对抗性代理和诚实代理的聚合更新。
$\Delta_{adv}$ 应该将模型的参数引导到 $w_{adv}$,可以最大限度地减少主任务和后门攻击任务的损失。
$\Delta_{hon}$ 想要将模型参数移向只会最小化主任务损失的模型参数。
- 鲁棒的学习率
假设 $w_{hon}$ 和 $w_{adv}$ 是不同的点,$\Delta_{adv}$ 和 $\Delta_{hon}$ 很可能在它们指定的方向上至少在某些维度上有所不同。假设对抗代理的数量是有限的,我们可以通过根据更新的符号信息调整服务器的学习率来确保模型远离 $w_{adv}$ 并转向 $w_{hon}$。
通过扩展 (Bernstein et al. 2018) 中提出的方法来构建一种防御,我们将其称为鲁棒学习率(RLR)。
在服务器端引入了一个称为学习阈值 $\theta$ 的超参数,对于每个更新符号总和小于 $\theta$ 的维度,学习率乘以 -1。这是为了最大化该维度上的损失,而不是最小化它。
在学习阈值为 θ 的情况下,第 i 个维度的学习率由下式给出,
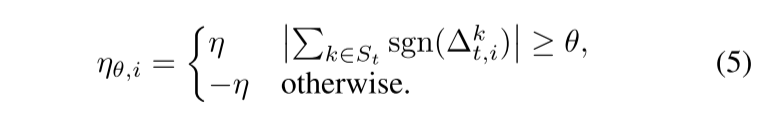
与 FedAvg 结合后的更新规则:
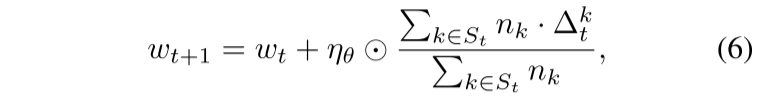
由于我们只调整学习率,因此该方法与聚合函数无关。例如,我们可以将它与更新裁剪和噪声添加简单地结合起来,如 (2) 中所示。
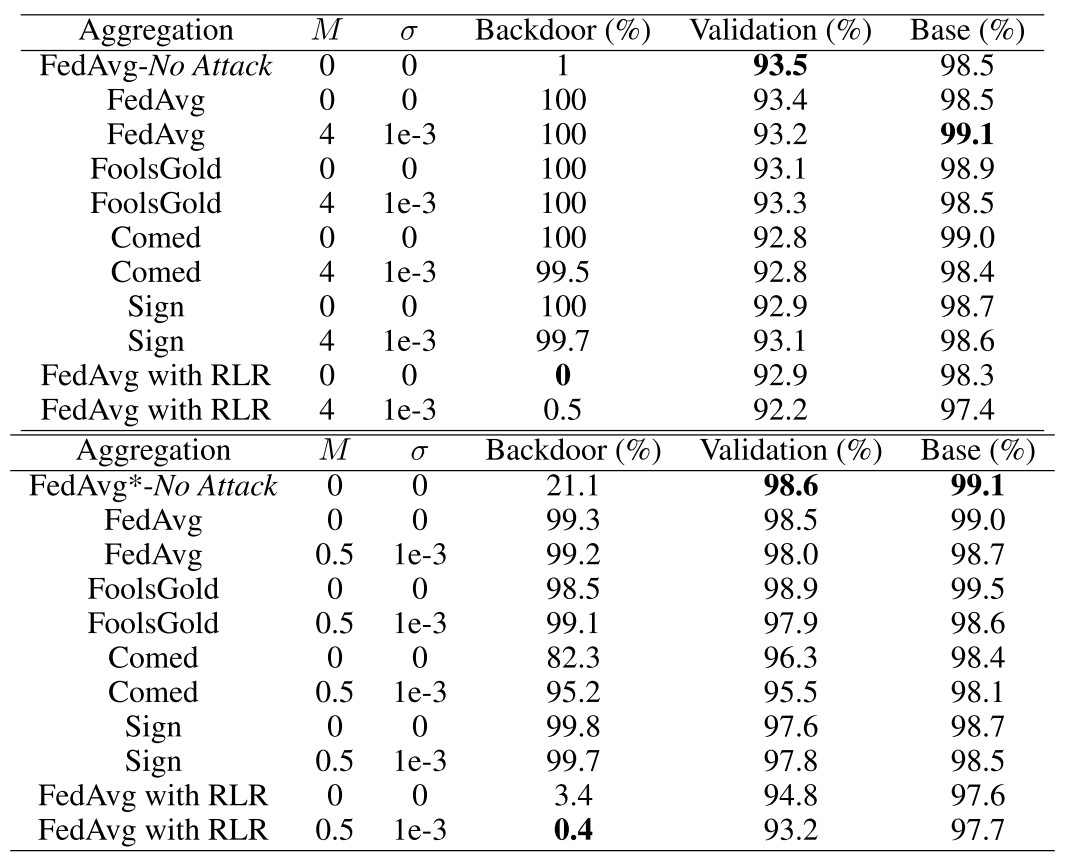
实验
- 数据集:Fashion MNIST(IID)和 Federated EMNIST(No-IID)
- 模型:具有两层卷积层,一层最大池层和带 Dropout 的两个全连接层的五层卷积神经网络
-
评价指标:验证准确率、基类准确率和后门准确率
- 木马基类和相应目标类示例
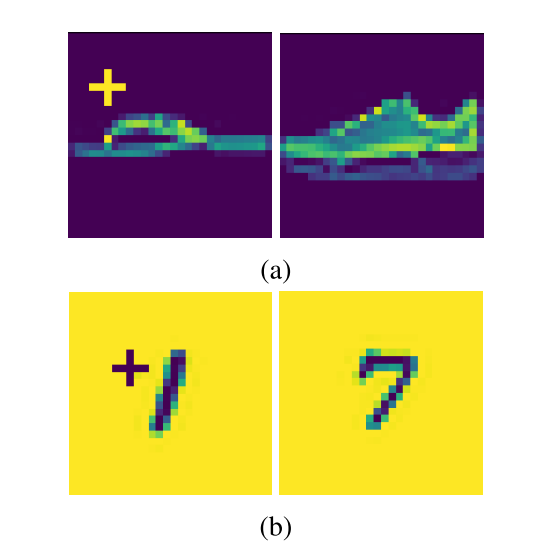
木马模式是一个 5×5 的加号,IID(上)和 No-IID(下)。
- 实验结果
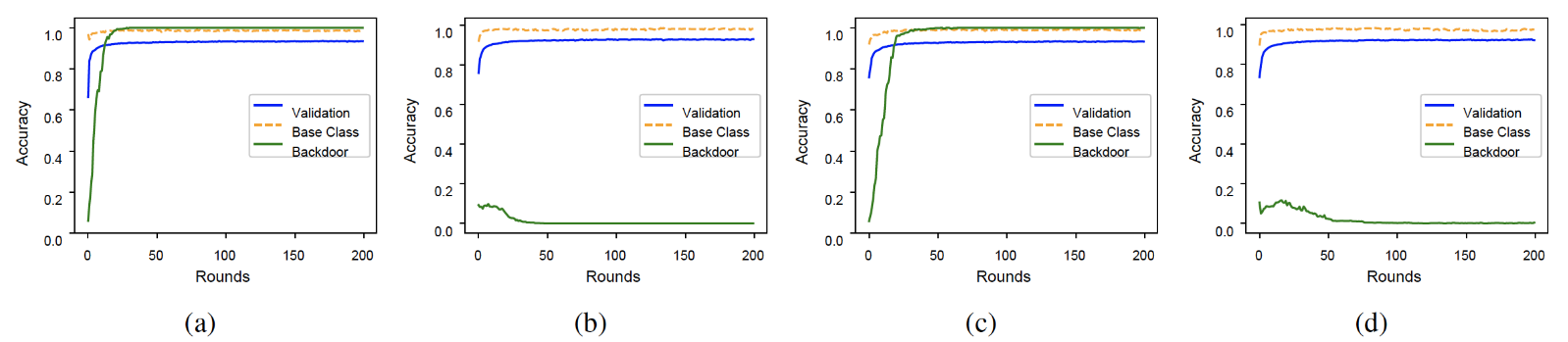
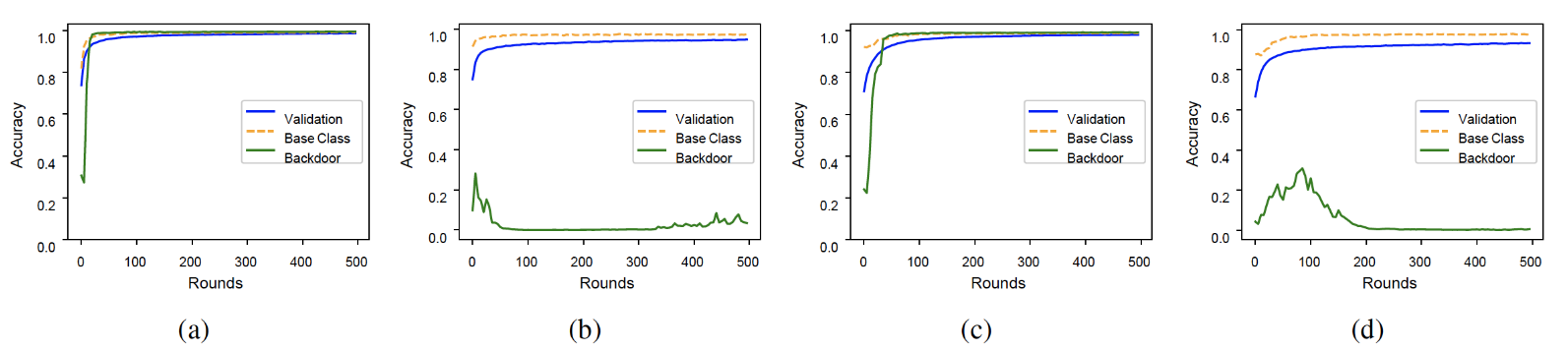
(a) FedAvg (b) FedAvg with RLR (c) FedAvg under clipping&noise (d) FedAvg with RLR under clipping&noise
RLR 防御提供了最好的保护,并且对验证准确性的影响最小。
- 优化
在防止后门任务方面,具有 RLR 率的 FedAvg 比其他方法的性能要好得多,但它也会降低收敛速度。
是否可以在没有 RLR 的情况下开始,然后在训练期间的某个时间点切换到 RLR ?
在模型即将收敛和/或怀疑存在后门攻击时切换到 RLR,以在训练期间清理后门模型,缩短收敛时间。
- 文中提出的防御为什么有效?

(a) FedAvg, (b) FedAvg with RLR in i.i.d. setting, and (c) FedAvg, (d) FedAvg with RLR in non-i.i.d. setting
净影响是诚实代理和对抗代理对木马样本映射的影响之间差异的累积总和。
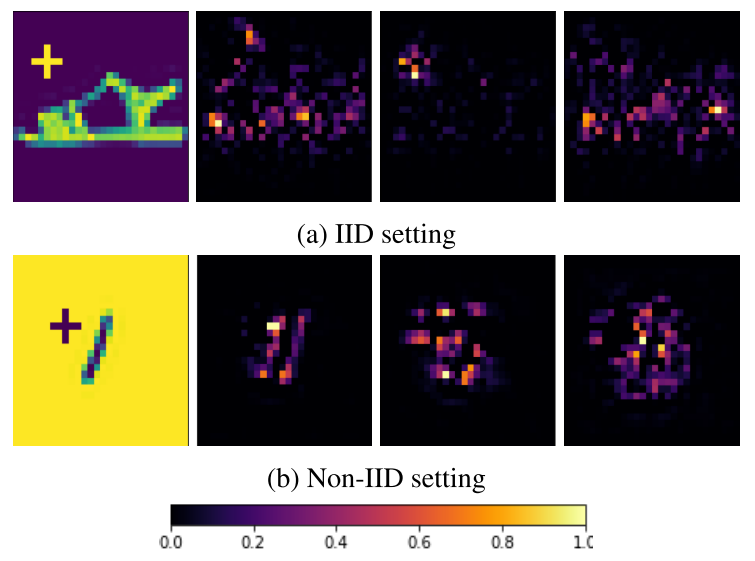
FM:使用 FedAvg 训练的模型的,没有任何攻击,FM:使用 FedAvg 训练的模型的,受到攻击,FM:使用 FedAvg 和 RLR 训练的模型的,遭到攻击。
总结
在这项工作中,作者从对抗的角度研究了 FL,并构建了一种简单的防御机制,特别是针对后门攻击。 防御背后的关键思想是根据代理更新的符号信息调整聚合服务器每维度和每轮的学习率。 通过实验,说明文中的防御大大降低了后门的准确性,而整体验证准确性的降级最小。总体而言,它优于文献中最近提出的一些防御措施。