| 论文英文名字 | DeepSight: Mitigating Backdoor Attacks in Federated Learning Through Deep Model Inspection |
|---|---|
| 论文中文名字 | DeepSight:通过深度模型检查减轻联邦学习中的后门攻击 |
| 作者 | Phillip Rieger, Thien Duc Nguyen, Markus Miettinen, Ahmad-Reza Sadeghi |
| 来源 | 29th NDSS 2022 [CCF 网络与信息安全 B 类会议] |
| 年份 | 2022 年 4 月 |
| 作者动机 | 现有的针对后门攻击的对策效率低下,并且通常仅旨在从聚合中排除偏离模型。但是,这种方法也会删除具有偏离数据分布的客户端的良性模型,从而导致聚合模型对此类客户端表现不佳。 |
| 阅读动机 | |
| 创新点 | 深入检查 NNs 的内部结构和输出,以识别具有高攻击影响的恶意模型更新,同时保持良性模型更新,即使这些更新来自具有偏离数据分布的客户端。 |
内容总结
对抗性困境
攻击者可以任意选择其攻击策略:一方面,它可以使用高比例的中毒数据来训练后门任务。但是,这会导致中毒模型与良性模型不同,从而使中毒模型易于被基于过滤的防御检测到。另一方面,如果对手不遵循此策略,则可以通过任何限制单个模型影响的防御措施轻松缓解攻击,因为中毒模型的数量超过良性模型。因此,将这两种防御策略结合起来会给对手带来两难境地:要么攻击被防御的一部分过滤,要么另一部分使攻击的影响可以忽略不计。
利用对手的困境
- 训练有素的后门模型:与良性模型有很大的不同
- 弱训练的后门模型:影响可能会变得微不足道
- 放大的后门模型:限制各个客户端的贡献
分析 ML 模型训练数据分布的技术
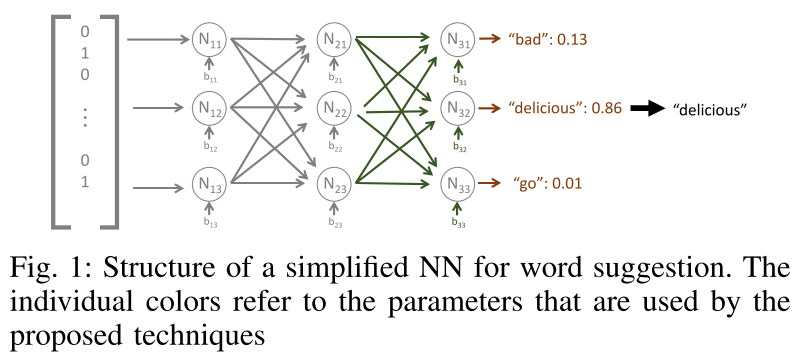
部门差异(DDifs)
原理:如果两个模型 $W_{t,i}$ 和 $W_{t,k}$ 在相似的数据上进行训练,那么它们的概率与全局模型的预测相比也将相似。通过这种技术获得的信息允许识别具有相似训练数据的客户。
数据:随机输入向量
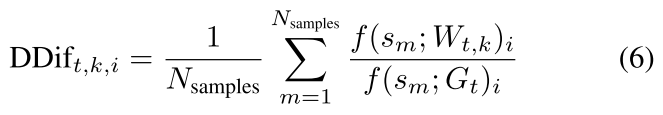
归一化更新能量(NEUP)
原理:输出层中神经元的更新的总大小会泄漏有关此更新的训练数据中标签的频率分布的信息。
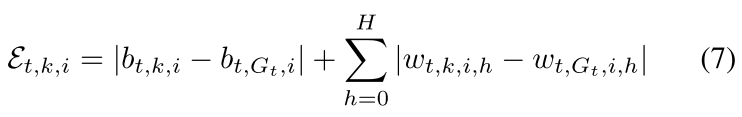
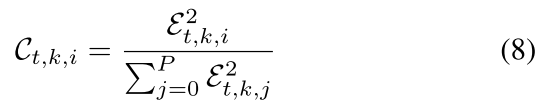
超出阈值
原理:中毒模型的训练数据的异质性明显低于良性模型的训练数据
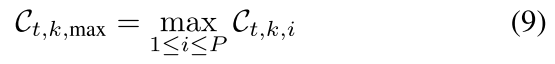
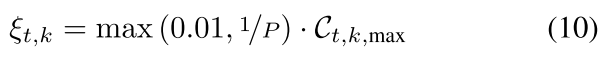
方法
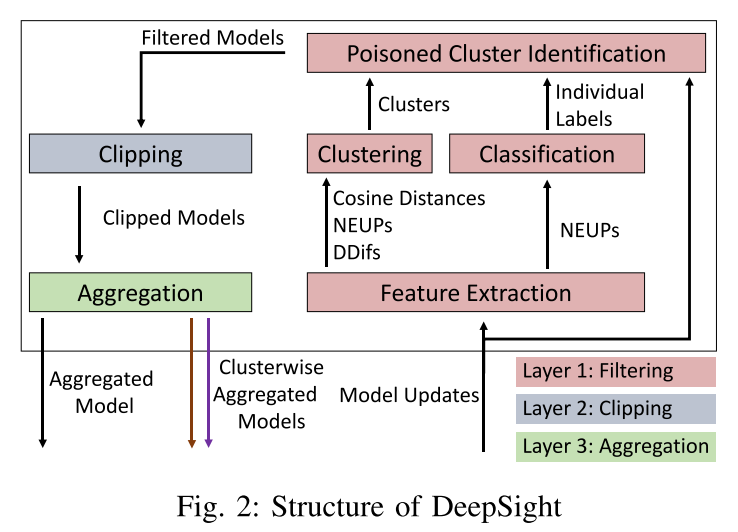
- 删除具有高攻击影响的中毒模型,其中训练数据集中在后门行为的样本上。
- 范数裁剪
过滤层
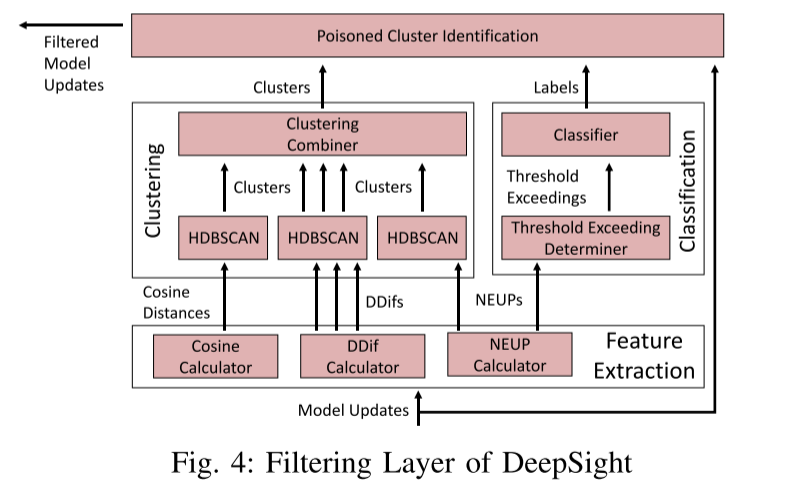


- 特征提取:计算余弦距离、NEUPs、DDift
- 分类:使用超出阈值表记模型更新(良性或可疑)
- 聚类:同一组中所有模型的训练数据均基于 IID 训练数据(基于 DDifs、NEUP 和余弦距离)
- 中毒集群识别:决定接受和拒绝模型
裁剪层
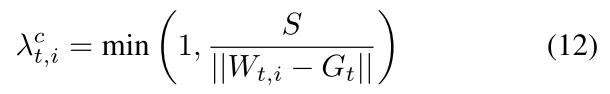
S 的选择:使用所有更新 (包括过滤掉的模型更新) 的 L2-norms 中位数动态选择
聚合层
聚合所有过滤剪裁后的模型更新。
在最后一轮中,聚合是按聚类方式执行的,并且还包括经过过滤的剪切模型。只有来自同一群集的模型被聚合在一起,并且每个客户端接收为相应群集聚合的模型。
实验
- 任务:文本预测和网络入侵检测系统
实验结果
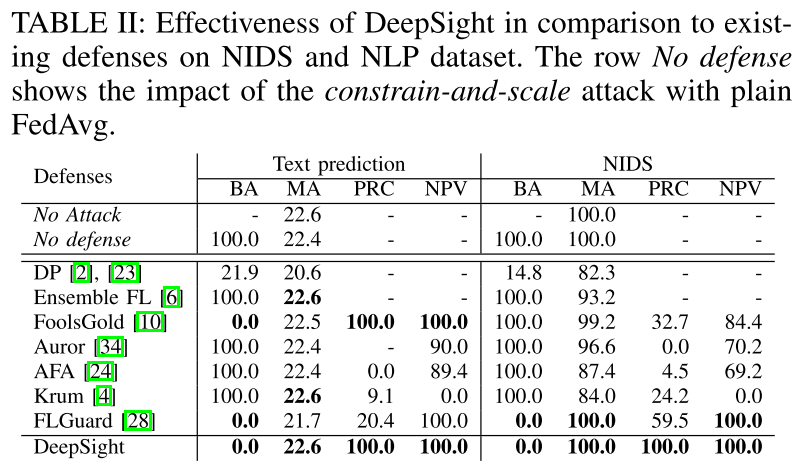

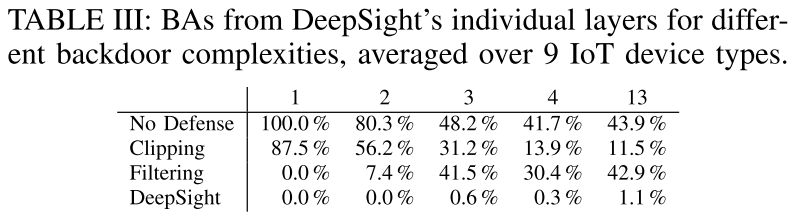
总结
- 主要解决模型过滤会使主任务准确率下降的问题。
- 与安全聚合不兼容,没有考虑隐私保护。