| 论文英文名字 | Defense against backdoor attack in fe derate d learning |
|---|---|
| 论文中文名字 | 联邦学习中的后门攻击防御 |
| 作者 | Shiwei Lu, Ruihu Li, Wenbin Liu, Xuan Chen |
| 来源 | Computers & Security, Volume 121 [CCF 网络与信息安全 B 类期刊] |
| 年份 | 2022 年 10 月 |
| 作者动机 | 现有的防御方案不能很好地防御 FL 中的模型替换攻击和自适应后门攻击。 |
| 阅读动机 | |
| 创新点 | 在模型收敛轮次和早期轮次防御后门攻击 |
内容总结
主要贡献
- 我们研究了 non-IID 联合设置中对大容量模型的后门攻击的特征,这表明可以利用冗余神经元来提高后门持久性并避免聚合后后门特征无效。
- 我们提出了一种用于收敛轮攻击的具有相似性测量的新防御方案。与现有的相似度度量方案不同,我们的方案是根据后门攻击的特点和脆弱性设计的,因此可以在FL中进行针对性的防御,时间复杂度更低,防御效果更好。
- 我们将一种在深度学习中具有后门神经元激活的检测方法移植到联邦学习中,并改进它以防御早期攻击。与原始检测相比,我们的方法使服务器能够自动检测并从聚合模型中删除嵌入式后门,并具有更好的性能。
- 基于 PyTorch 框架和联合平均(Fed-Avg)聚合规则的实验对后门攻击和我们的防御方案进行。结果表明,在收敛轮攻击下,与基准防御相比,我们的相似性测量防御在模型替换攻击(提高 25%)和自适应攻击(提高 67%)上都获得了最高的检测精度,而另一种具有后门神经元的防御激活可以去除后门并保持聚合模型在早轮攻击下的主要任务准确性。
预备知识
联邦学习
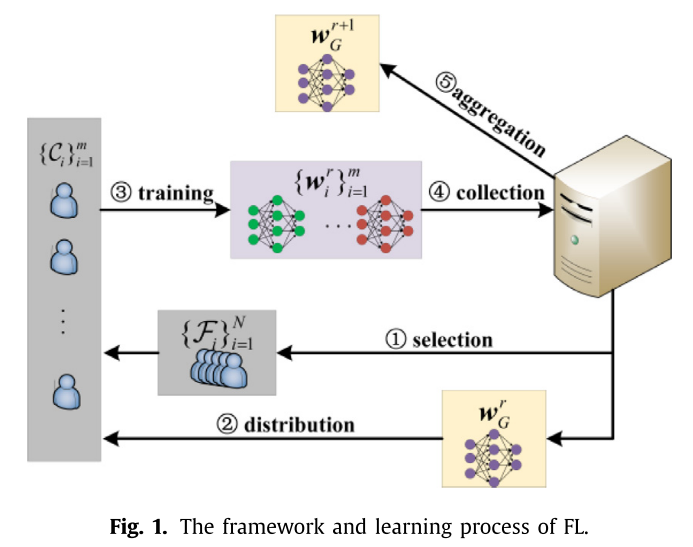
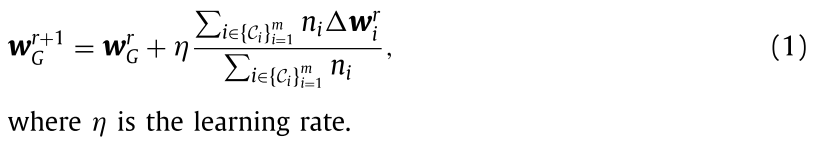
后门攻击
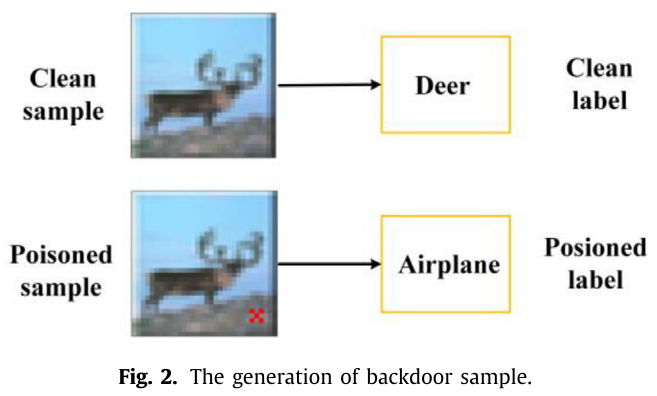
攻击者通过以下步骤发起后门攻击:(1)生成带有目标标签 $y_{target}$ 的中毒样本 $\hat{x}$;(2)将中毒样本 $\hat{x}$ 与干净样本 $x$ 混合进行训练。


自适应后门攻击
将损失项 $\ell_{ano}$ 引入模型损失函数 $\ell_{model}$ 进行模型训练:

模型替换攻击的持久性
在模型替换攻击中,攻击者训练一个后门模型 $w_j^{backdoor}$ 并将(6)中的恶意更新 $\Delta_j^r$ 发送到服务器,旨在用近似后门模型 $w_j^{backdoor}$ 替换全局模型 $w_G^{r+1}$。然而,在 FL 中多次聚合后,聚合模型的参数分布会发生变化,因此嵌入的后门可能会逐渐失效。
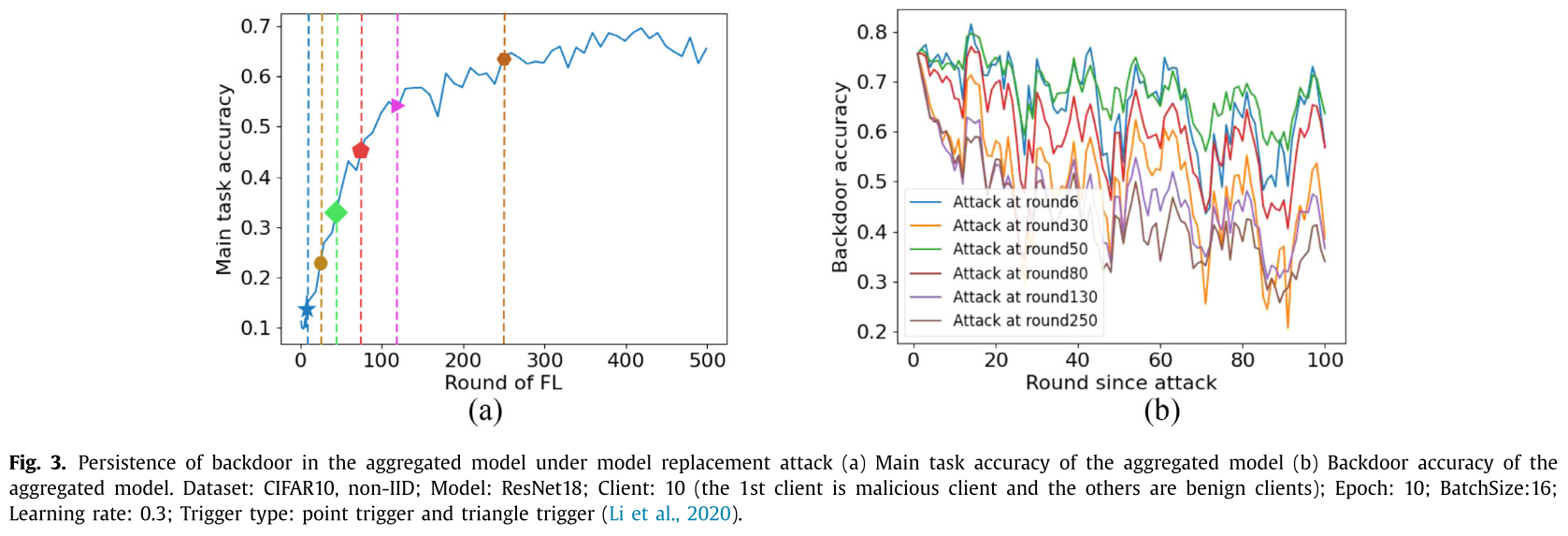
- 在实验的早期轮次中注入的后门仍然保留在聚合模型中。
- 无论我们在哪一轮发起模型替换攻击,在 non-IID 设置下,聚合模型的后门精度逐渐降低。
根据发起攻击的轮次,将 FL 中的后门攻击分为两类:收敛轮次攻击和早期轮次攻击。
用相似度度量防御收敛轮攻击
动机
在收敛轮生成的恶意更新 $\Delta w_j^r$ 几乎与 $(w_j^{backdoor}−W_G^r)$ 成正比。
方法
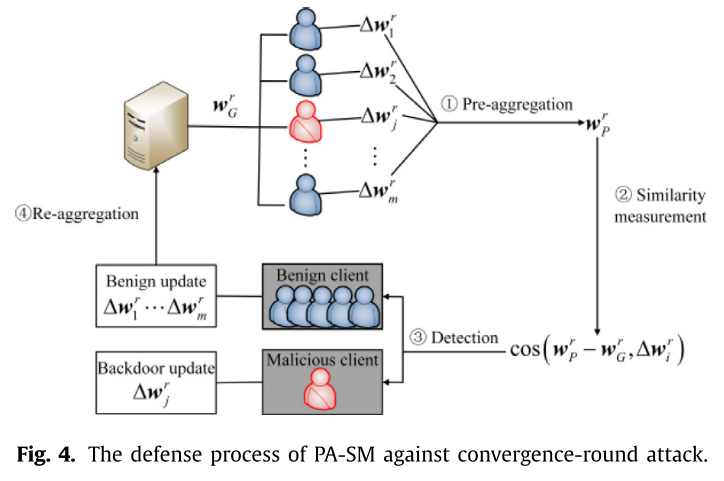
- 在获得聚合模型之前添加一个预聚合,聚合所有客户端的更新;
- 计算第 r 轮预聚合模型
$w_p^r$; - 计算余弦相似度
$cos(w_p^r-w_g^r, w_i^r)$; - 如果
$cos(w_p^r-w_g^r, w_i^r) \geq \lambda$,则第 i 个更新将被检测为恶意更新并从更新集中删除;否则,这是一个良性更新。
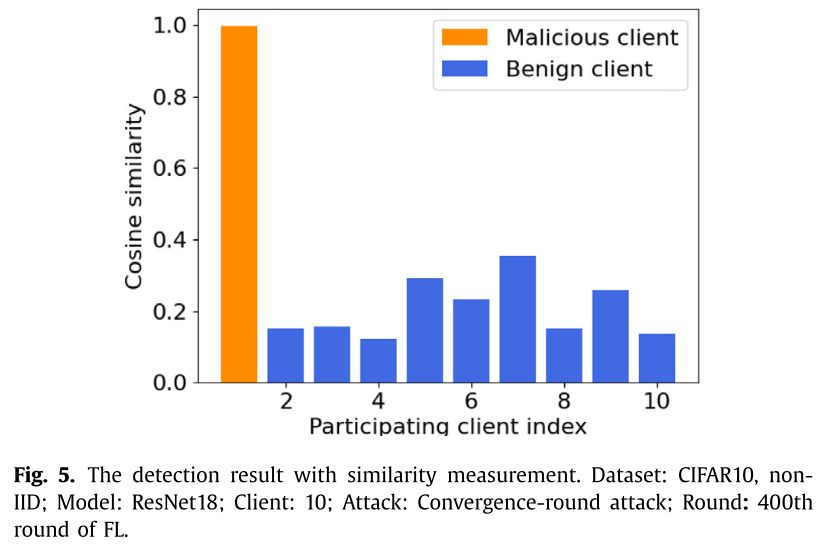
$\lambda=0.95$
优点
- 攻击者不能通过自适应后门攻击来逃避防御。(攻击者只能通过调整
$\Delta w_j^r$去改变$cos(w_p^r-w_g^r, w_i^r)$。) - 具有较少的计算开销。(计算局部更新和预聚合更新之间的余弦相似度,因此时间复杂度为
$O(d·m)$。)
问题
在早期攻击中,尽管最终模型的后门准确性降低,但它可以确保攻击逃避了我们的检测方案,并且最终模型会记住一些后门特征。然而,PA-SM 中的预聚合模型 $w_p^r$ 与后门模型 $w_j^{backdoor}$ 有很大不同。因此,PA-SM 防御在早期攻击中是无效的。
通过后门神经元激活防御早期攻击
动机
后门模型在某些坐标上表现出出乎意料的高神经元激活,因为它在后门输入上产生鲁棒的特征表示和错误分类。
DF-TND
$r_i(x)$ 是干净输入 $x$ 的神经元激活向量的第 $i$ 个坐标。由于 FL 中的服务器不能从客户端收集数据集,因此在该检测器中选择随机噪声模式作为干净的输入 $x$,其大小与客户端的本地数据相同。DF-TND 寻求最优触发器来构建(2)中用 $\delta$ 和 $m$ 参数化的恢复模式 $\hat{x}(\delta, m)$,其可以最大化后门神经元 $r(\hat{x}(\delta, m))$ 的激活。
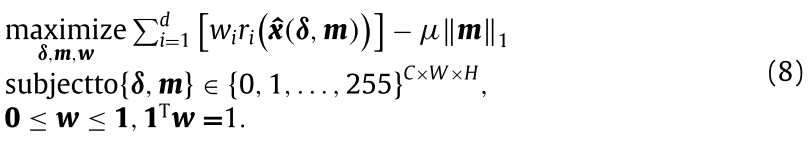

假设在分类任务中存在 $N_1$ 个用于检测的随机种子模式和 $K$ 个类别。对于每个类别 $k \in [K]$,我们可以在第 $k$ 个类别上获得局部模型的异常分数:
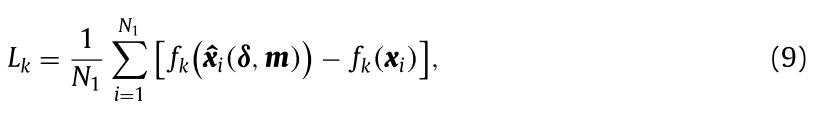
对于给定的阈值 $T$,如果 $L_k > T$,则该模型被检测为后门模型,并且第 $k$ 个类别是攻击目标类别。
问题:(1)DF-TND 的效果取决于主任务精度和后门任务精度。(2)超参数 $T$ 难以自动选择,这可能会影响检测效率。
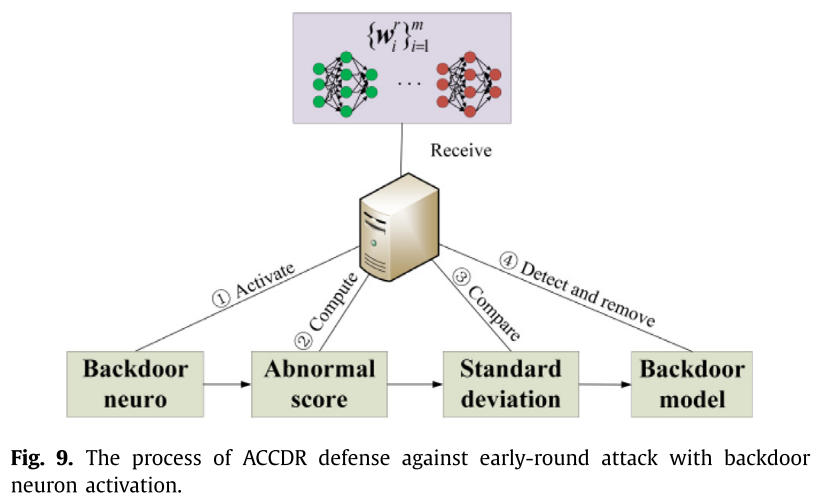
ACCDR
后门模型和良性模型的主要区别在于恢复模式的神经元表示。
- 使用
$N_1$个随机模式通过求解优化问题(8)得到它们的神经元表示$r(\hat{x}(\delta, m))$和$r(x)$; - 计算第
$k$个模型的异常分数$L_k(k=1,...,m)$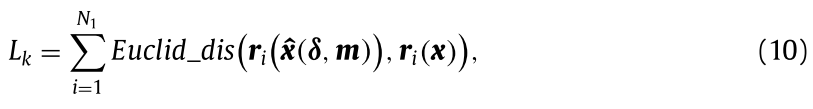 ;
; - 计算聚合模型的异常分数;
- 计算所有异常分数的标准差,记为
$std(L_1,L_2,...L_m,L_G)$ - 如果攻击者在第
$r(r \neq 1)$轮发起后门攻击,比较$std(L_1^r,L_2^r,...L_m^r,L_G^{r+1})$和$std(L_1^{r-1},L_2^{r-1},...L_m^{r-1},L_G^r)$是一种适合自动检测后门攻击的方法,其中假设第$r-1$轮没有攻击。
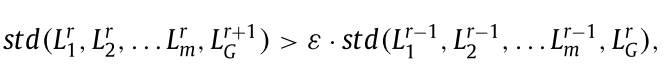
可以推断 FL 中存在后门攻击,其中 $\epsilon$ 是确定检测效果的控制参数。
由于恢复模式可以激活后门模型中的后门神经元,而种子模式不能激活它们,因此在后门模型中神经元表示向量 $r_i(\hat{x}(\delta, m))$ 与 $r_i(x)$ 有很大不同。(标准差)
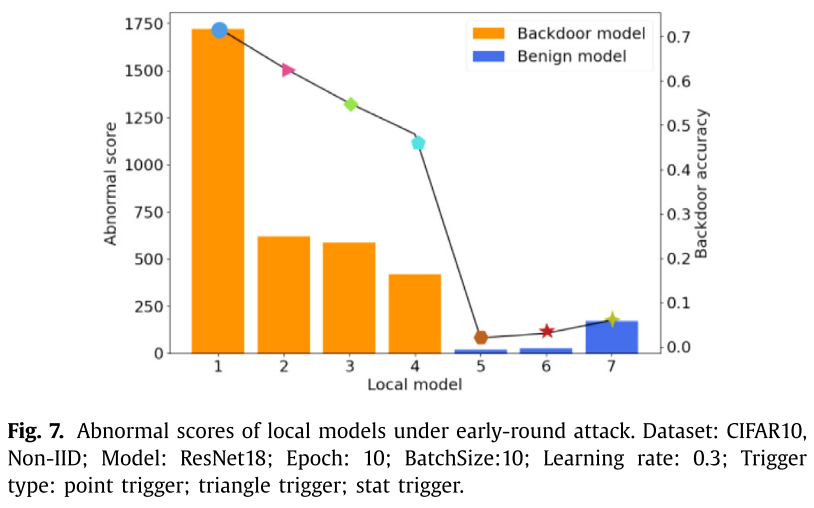
- 后门模型的异常分数明显大于良性模型
实验
- 数据集:GTSRB 和 CIFAR10
- 数据分布:non-IID
- 训练模型:ResNet18
收敛轮次攻击下防御方案的性能分析
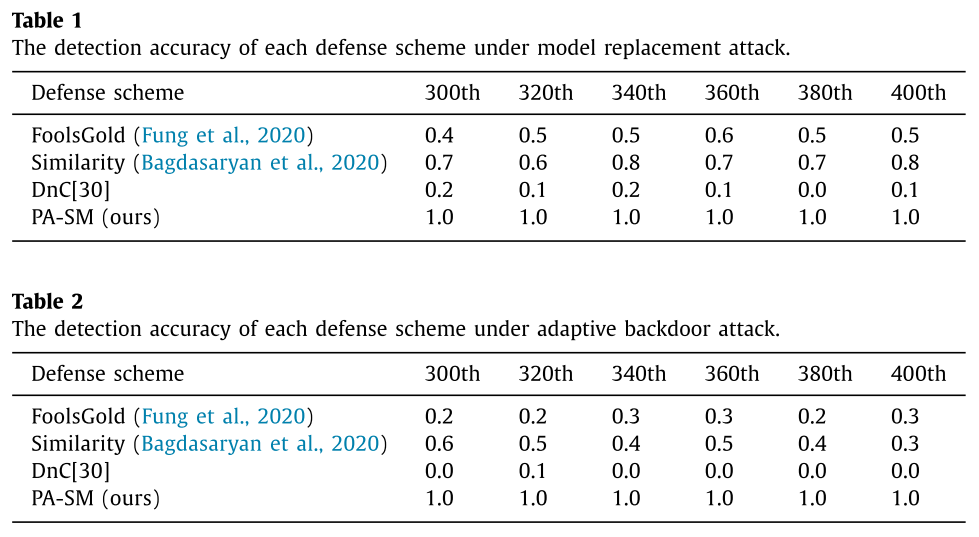
- PA-SM 获得了最高的检测精度
早期轮次攻击下防御方案的性能分析
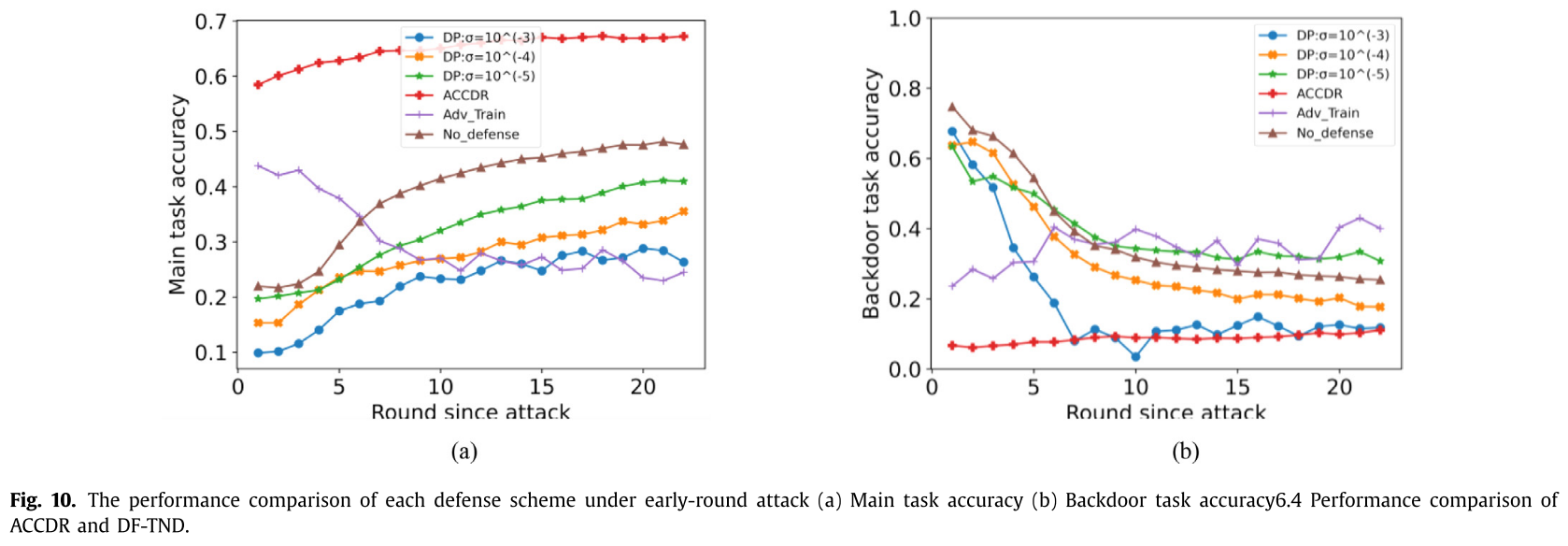
- ACCDR 防御效果好
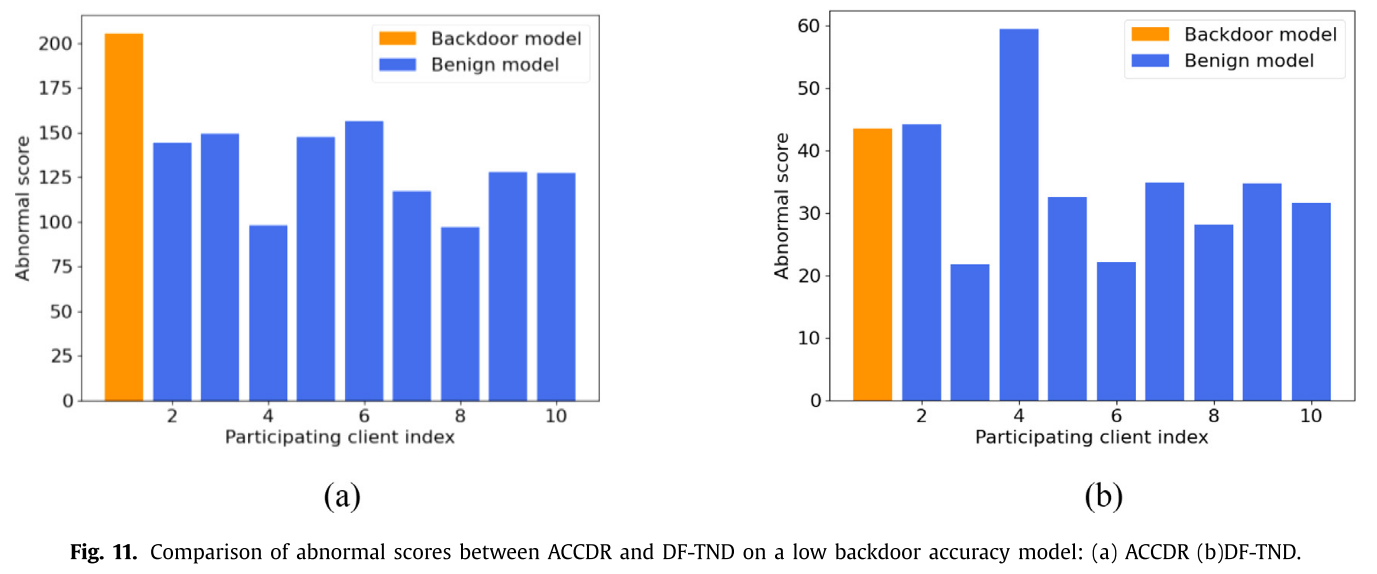
- ACCDR 对后门模型的检测效果优于 DF-TND。
结论
在本文中,根据后门攻击的持久性和特点,我们设计了 PA-SM 和 ACCDR 两种防御方案,分别在模型收敛轮次和早期轮次防御后门攻击。与基准防御相比,PA-SM 在收敛轮攻击中可以获得最佳和最稳定的检测性能。而且,PA-SM 检测算法的时间复杂度最低。由于攻击者可能会选择早轮攻击来规避 PA-SM,因此提出了 ACCDR 来检测和去除具有后门神经元激活的后门模型。与差分隐私和对抗性训练相比,ACCDR 可以快速去除后门并保持聚合模型的主要任务准确性。鉴于 ACCDR 的时间复杂度高,我们认为它更适合部署在 FL 的早期轮次中,而 PA-SM 是一种更方便的方案来防御模型收敛轮次中的后门攻击。在未来的工作中,我们将探索 FL 中的拜占庭后门攻击,其中可能会同时制作多个恶意模型来逃避防御。