| 论文英文名字 | FederatedReverse: A Detection and Defense Method Against Backdoor Attacks in Federated Learning |
|---|---|
| 论文中文名字 | FederatedReverse:一种针对联邦学习中后门攻击的检测和防御方法 |
| 作者 | Chen Zhao, Yu Wen, Shuailou Li, Fucheng Liu, Dan Meng |
| 来源 | 9th IH&MMSec 2021: Virtual Event, Belgium [CCF 网络与信息安全 C 类会议] |
| 年份 | 2021 年 6 月 |
| 作者动机 | 大多数后门防御技术不适用于联邦学习,因为它们基于在联邦学习方案中无法保存的整个数据样本。新提出的联邦学习方法牺牲了模型的准确性,并且一旦攻击在许多训练回合中持续存在,仍然失败。 |
| 阅读动机 | |
| 创新点 | 逆向工程、全局反向触发器生成、异常值检测和模型修复 |
内容总结
主要贡献
- 在不违背联邦学习设计原则的前提下,提出了一种在联邦学习中检测和防御后门攻击的有效方法 FederatedReverse。
- 该解决方案降低了联邦学习中后门攻击的成功率,同时保持了主任务的准确性。
- 我们在多个图像识别任务上实现并验证了所提出的解决方案,例如手写数字识别和道路交通标志识别任务。通过与现有的联邦学习防御方法进行比较,证明了该方案在防御联邦学习后门攻击方面具有更好的性能。
预备知识
模型替换
联邦学习公式:
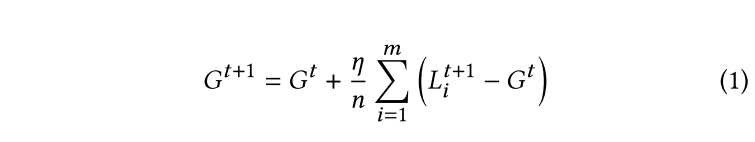
模型替换:
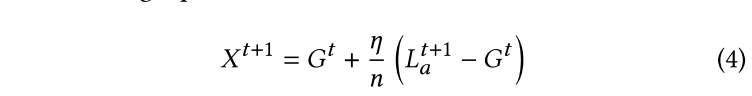
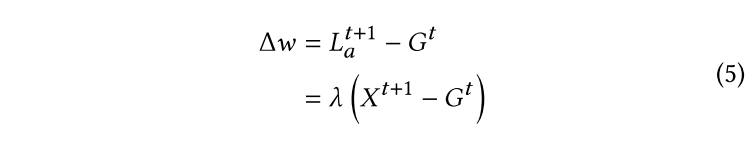
分布式后门攻击
后门攻击:
分布式后门攻击:
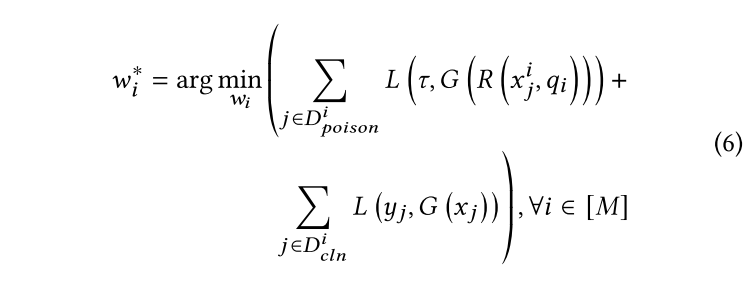
威胁模型
对手目标
通过向中央服务器提交本地恶意模型更新,将后门注入全局模型。
受污染的模型将对带有触发器的输入进行错误分类,但会正确标记剩余的输入。
对手的能力
- 攻击者可以完全控制联邦学习中的一个或多个参与者。
- 攻击者可以控制受感染参与者的本地数据、本地训练过程以及提交给中央服务器的模型更新。
- 攻击者无法访问用于更新全局模型的联邦学习聚合算法,也无法控制其他良性参与者的训练过程。
防御目标
提出一种针对联邦学习中现有后门攻击 (尤其是模型替换攻击和分布式后门攻击) 的检测和防御方法。
该方法可以在联邦学习训练过程中检测全局模型是否受到攻击,并在不影响主要任务准确性的情况下降低后门攻击的成功率。
防御者的能力
防御者无法直接访问每个参与者提交的参与者数据和模型更新。否则,防御者将违反联邦学习的设计原则,导致用户隐私数据泄露。
方法
概述
FederatedReverse 包括逆向工程、全局反向触发器生成、异常值检测和模型修复四个部分。
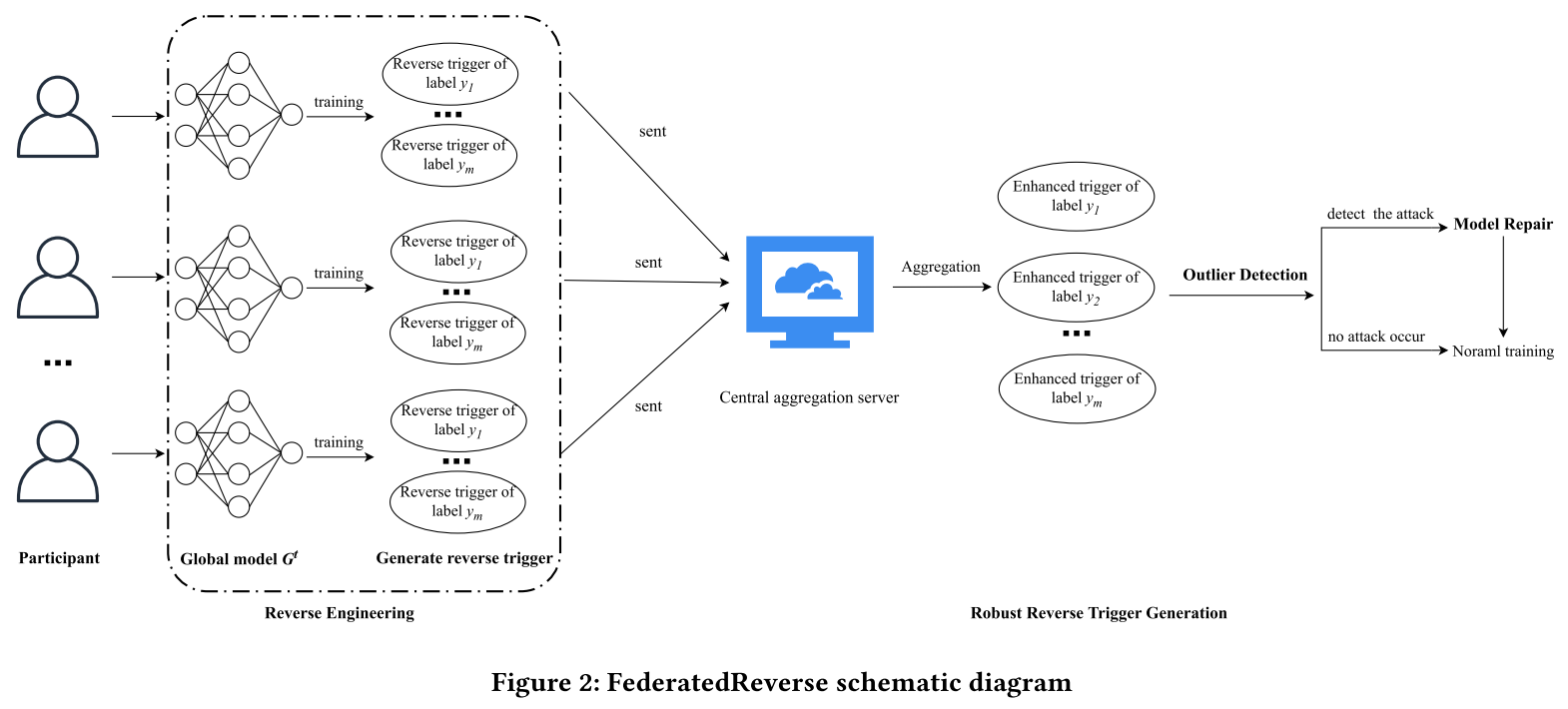
- 每个参与者对恶意模型
$G^t$进行逆向工程,以获得每个标签对应的本地反向触发器,并将这些本地反向触发发送到中央聚合服务器。 - 中央聚合服务器对接收到的相同标签的本地反向触发器进行聚合操作,以获得更鲁棒的全局反向触发器。
- 中央服务器通过检测全局反向触发器上的异常值来确定上一轮的全局模型
$G^t$是否受到攻击。 - 如果
$G^t$受到攻击,则需要在参与者的本地训练期间进行模型修复。
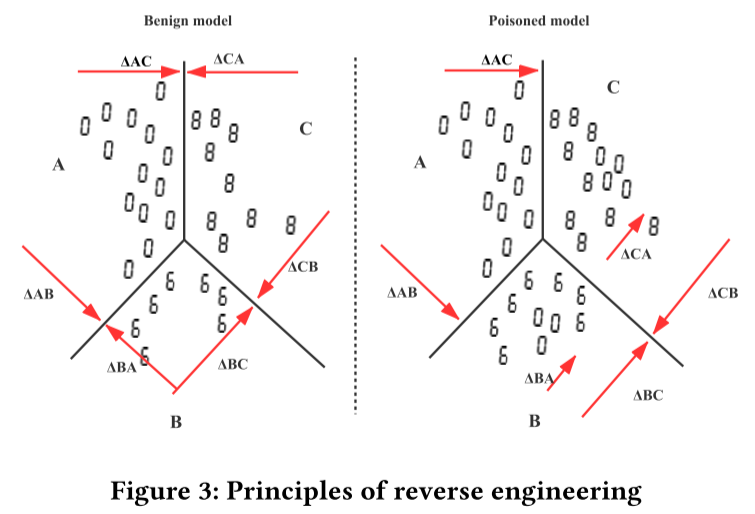
逆向工程
作用:计算将所有样本识别为指定标签所需添加的最小扰动。
原理:当模型遭受后门攻击时,受感染的标签对所有样本的扰动将比正常标签少得多。
带有触发器的图像:
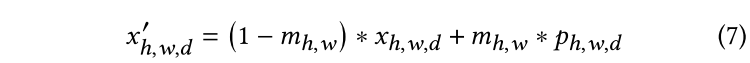
训练反向触发的目标函数:
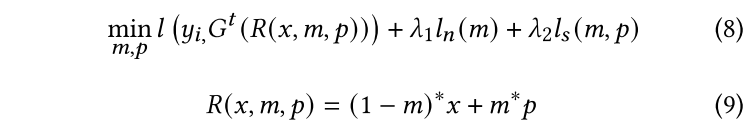
全局反向触发器生成
- 每个参与者将本地生成的本地反向触发器发送到中央服务器;
- 服务器需要使用密度聚类算法 DBSCAN 对相同标签不同参与者的本地反向触发器来丢弃与异常值对应的参与者;
- 使用联邦学习的中央聚合服务器来聚合每个本地触发器,最终获得更鲁棒的全局反向触发器。
为什么要使用全局反向触发器?
一些参与者对干净标签的局部反向触发效果差异很大
- 联邦学习中数据分布的 no-iid 特性和数据不平衡。
- 在少数情况下,我们发现神经网络训练的感染标签对应的局部反向触发器可能会出现模式崩溃。
异常值检测
在获得对应于每个标签的全局反向触发器之后,需要对全局触发器的大小执行离群点检测。
- 大小:全局反向触发器的
$\ell_1$范数来 - 离群点检测算法:绝对中值法
异常分数 $S_{abn}$ 定义为数据的绝对偏差除以绝对中值。将 $S_{abn}$ 大于 2 的任何数据点标记为异常值。
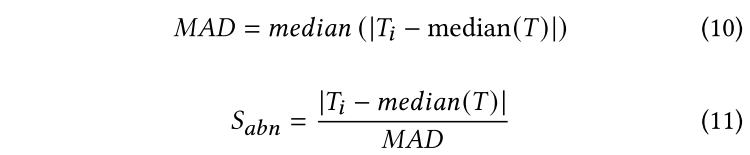
模型修复
方法:遗忘技术
在某轮训练中,将感染标签对应的全局反向触发器添加到干净的训练数据中,但这些数据的标签并没有改变。在使用这些数据进行训练时,模型会逐渐修改与此触发器相关的权重。最后,该模型将消除该触发器的影响,实现对后门攻击的防御。
实验
- 数据集:MNIST 和 GTSRB
- 数据分布:no-iid
- 训练模型:简单 CNN 网络 和 轻量 Resnet-18
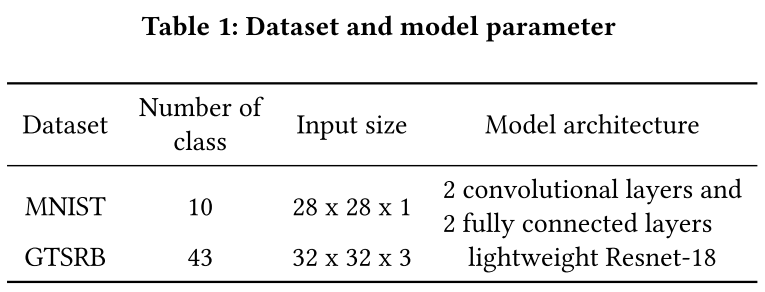
- 攻击:单发攻击和多发攻击 / 集中式后门攻击和分布式后门攻击
- 评估指标:攻击成功率(ASR)和主要任务准确率。
实验结果
异常值检测
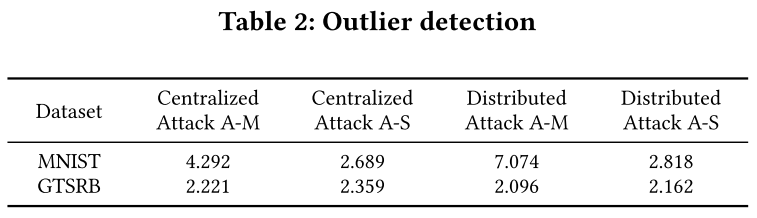
- 被攻击标签的异常分数都大于 2,因此我们认为模型受到攻击。
- MNIST 数据集的反向触发异常分数一般高于 GTSRB 数据集。
无触发器聚合的异常值检测
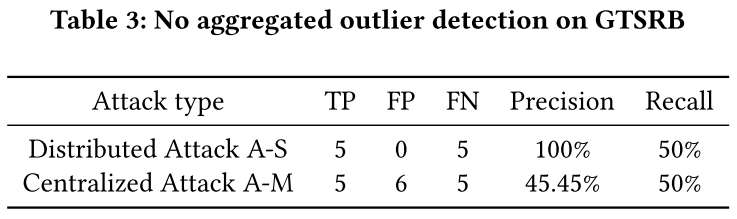
- 如果本地反向触发器不聚合,则召回率为 50%。换句话说,异常检测算法认为攻击者的反向触发器是正常的。
FederatedReverse 的防御效果
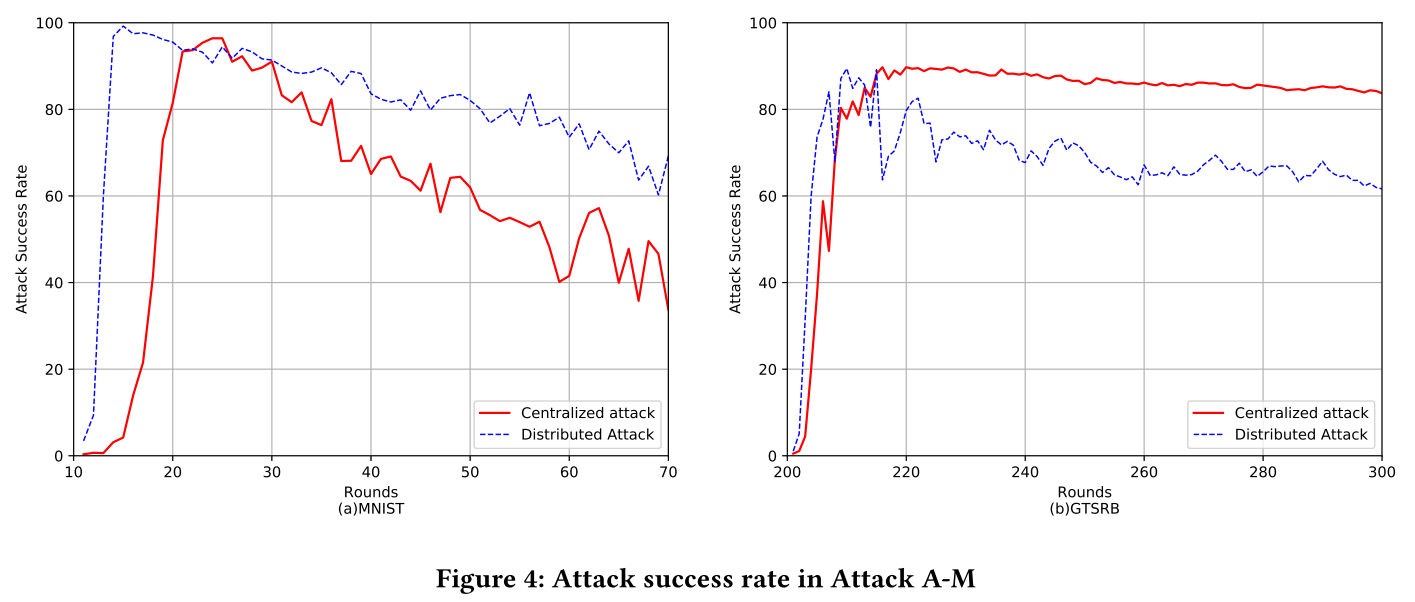
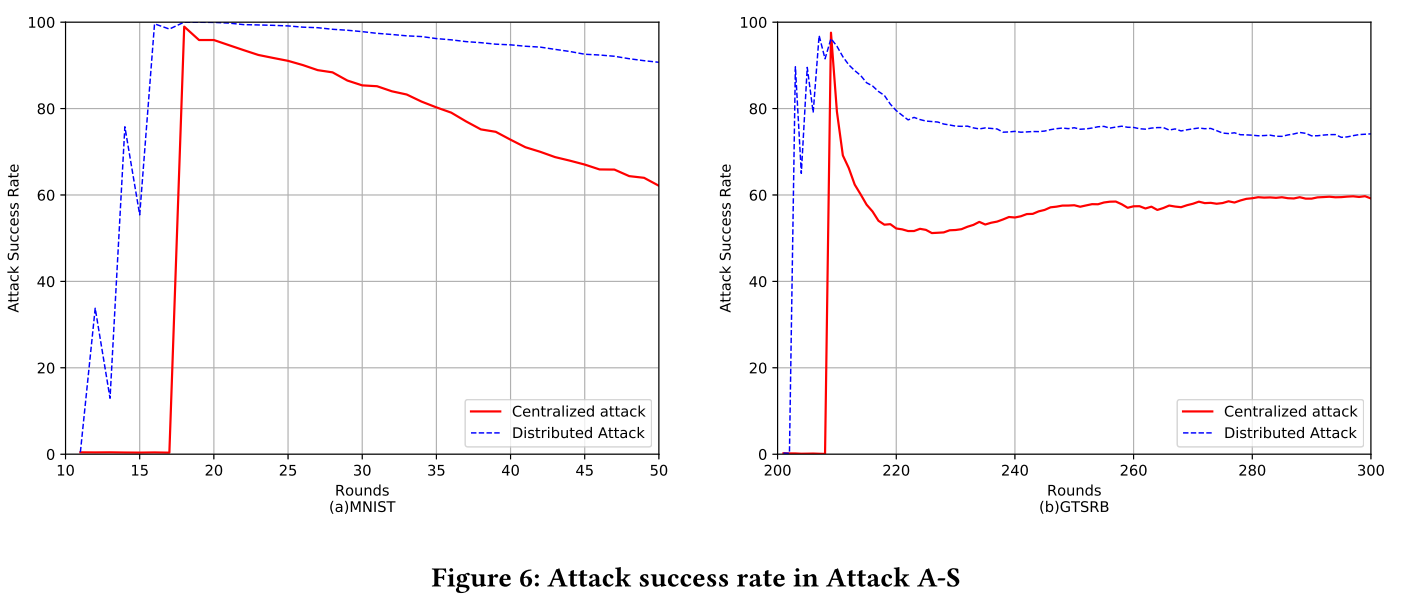
- 攻击成功率将大幅提升至 90% 左右,并且后门会在后续模型训练中持续很长时间。
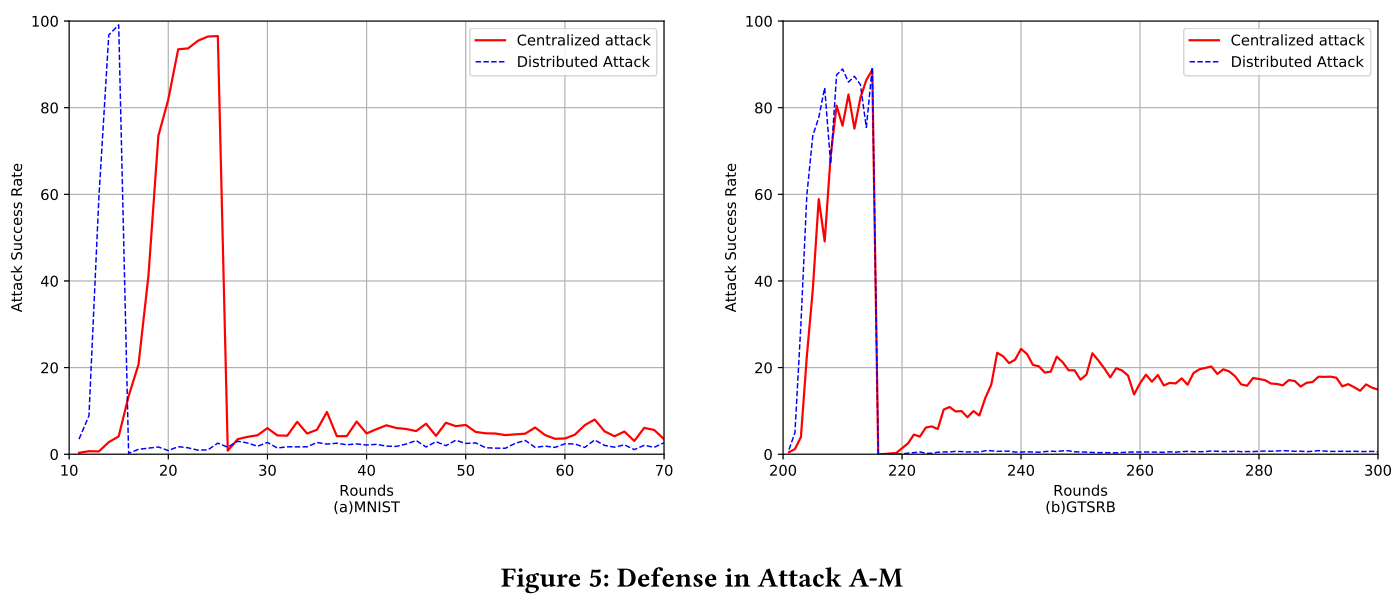
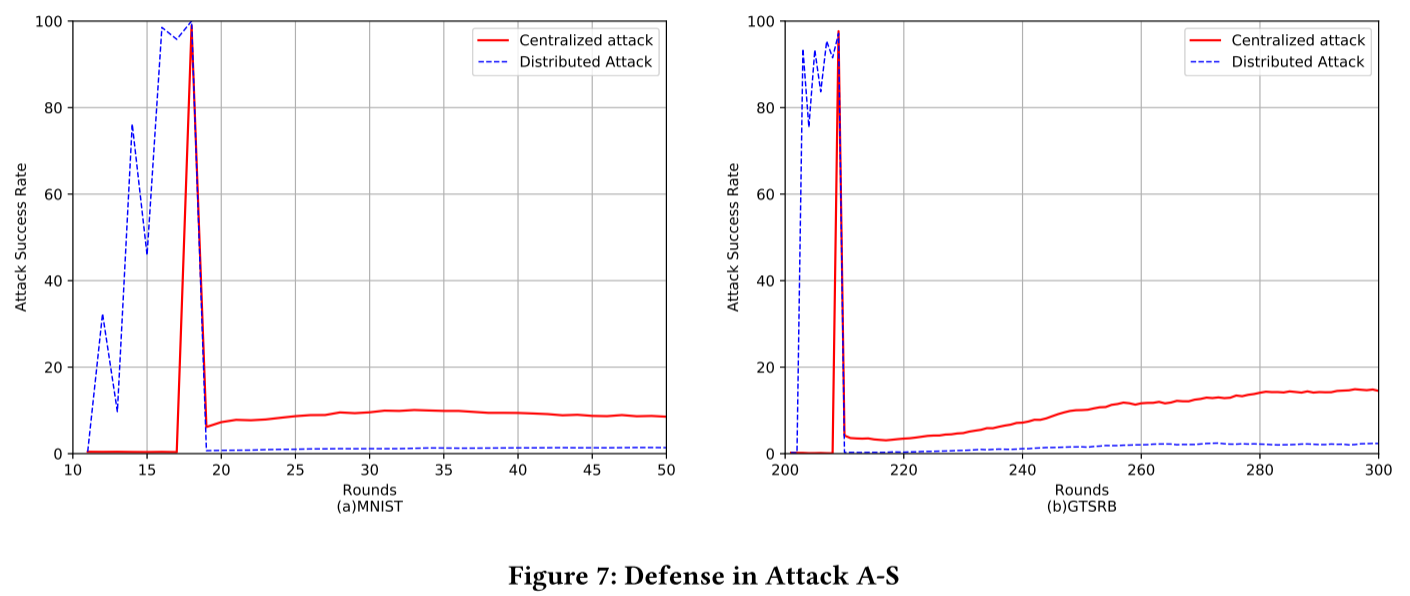
- 后门成功率
- 后门持续时间
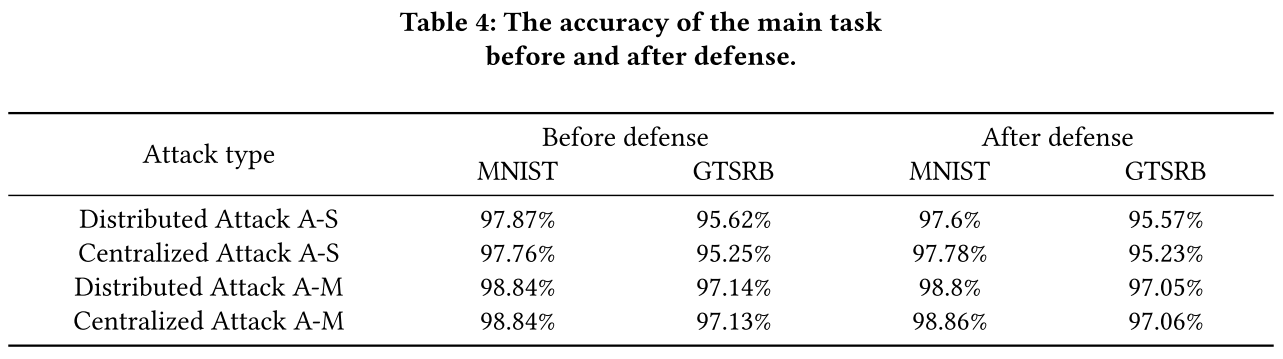
- 防御前后主任务的准确率变化很小
与现有防御方法的比较
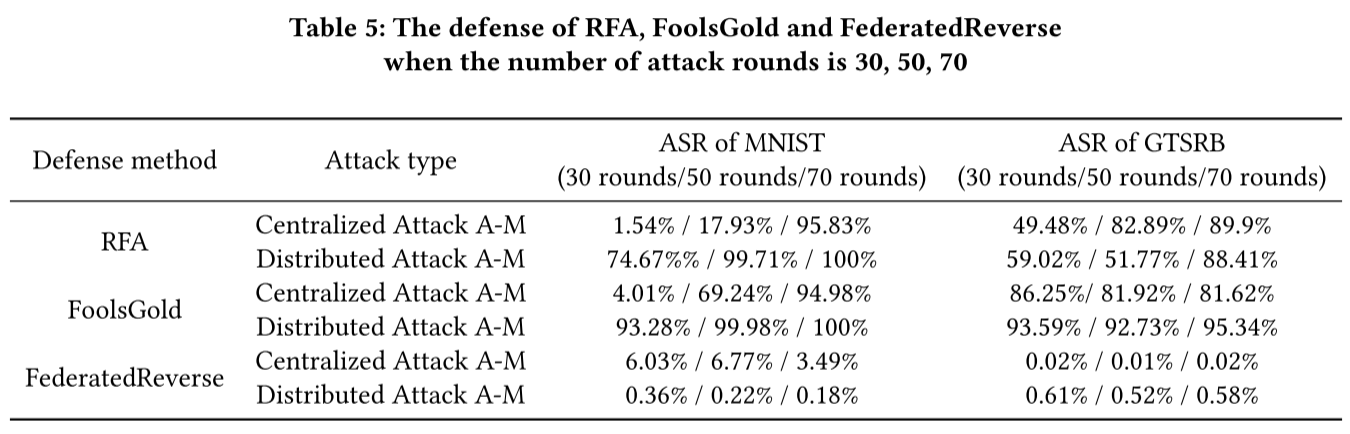
- 随着攻击回合次数的增加,后门攻击的成功率逐渐上升到 90% 左右,最终导致前两种算法的彻底失败。
- 在使用 RFA 和 FoolsGold 时,主要任务的准确性大大降低。
总结
本文提出了基于逆向工程和鲁棒全局反向触发器的 FederatedReverse 方法,能够有效检测图像识别领域的联邦学习后门攻击,并通过模型修复消除攻击者植入的后门影响。与现有工作相比,我们的方法降低了后门攻击的成功率,同时保证了主要任务的准确性不受影响。此外,该方法对攻击轮数的增加具有鲁棒性。该方法在联邦学习中四种常见攻击的检测和防御方面取得了可喜的成绩。
参考
问题
- 恶意客户端上传正常反向触发器后再进行后门攻击?
- 对后面攻击进行准确的定义? 在联邦学习中,后门攻击是意图让模型对具有某种特定特征的数据做出错误的判断,但模型不会对主任务产生影响。