| 论文英文名字 | Resisting Distributed Backdoor Attacks in Federated Learning: A Dynamic Norm Clipping Approach |
|---|---|
| 论文中文名字 | 在联邦学习中抵抗分布式后门攻击:一种动态范数裁剪方法 |
| 作者 | Yifan Guo, Qianlong Wang, Tianxi Ji, Xufei Wang, Pan Li |
| 来源 | BigData Conference 2021: Orlando, FL, USA [CCF 交叉/综合/新兴 C 类会议] |
| 年份 | 2021 年 12 月 |
| 作者动机 | 最近,范数裁剪方法被开发用来有效防御 FL 中的分布式后门攻击,该攻击不依赖于本地训练数据。然而,我们发现对手仍然可以通过稳健的训练绕过这种防御方案,因为它的范数裁剪阈值固定的。 |
| 阅读动机 | |
| 创新点 | 动态调整局部更新的范数裁剪阈值 |
内容总结
主要贡献
- 实验研究表明,固定范数裁剪方案可以被绕过,因为它在训练过程中的固定阈值不能捕捉到全局模型收敛过程中良性局部更新的动态特性。
- 为了解决这个问题,作者设计了一种新的自适应规范裁剪防御来缓解分布式后门攻击。
- 在四个公共数据集上的大量实验结果验证了我们提出的方案在缓解分布式后门攻击方面的有效性。特别地,与现有的防御方法相比,我们的动态范数裁剪方法显著降低了84.23% 的攻击成功率。
预备知识
由一个服务器节点和 n 个客户端节点组成的联邦学习系统。目标是找到以下问题的最优解:
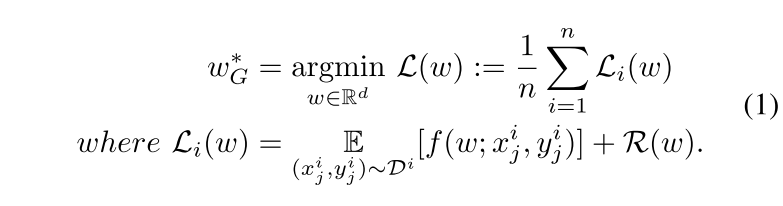
服务器聚合公式:
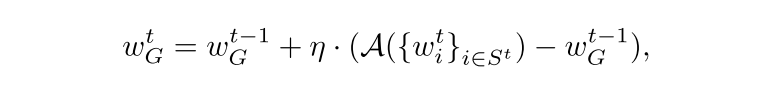
分布式后门攻击中攻击者 i 的目标:
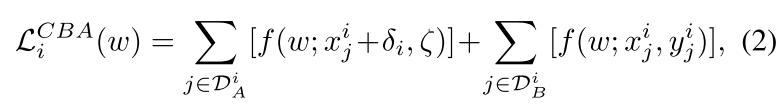
一种动态的规范裁剪方法
大规模恶意本地更新的必要性。
在没有权重重缩放操作的情况下,攻击者无法轻易地仅通过等式 2 利用后门触发器进行对抗性本地训练来实现其恶意目标。
绕过范数裁剪防御
范数裁剪:在聚合之前限制本地更新的范数,裁剪局部更新以确保其 $\ell_2$ 范数的上限是一个阈值 $M$。
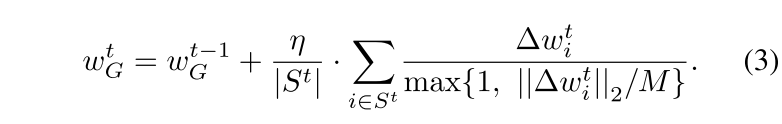
$M$ 是训练过程的固定吞吐量。选择适当的阈值 $M$ 对防御的有效性至关重要。
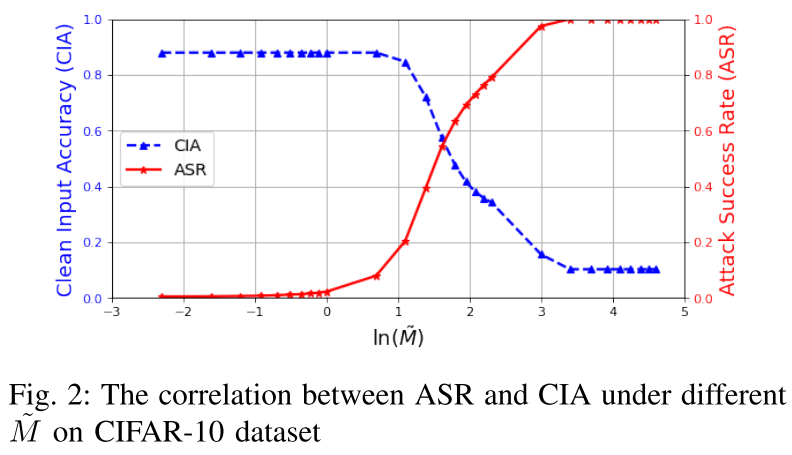
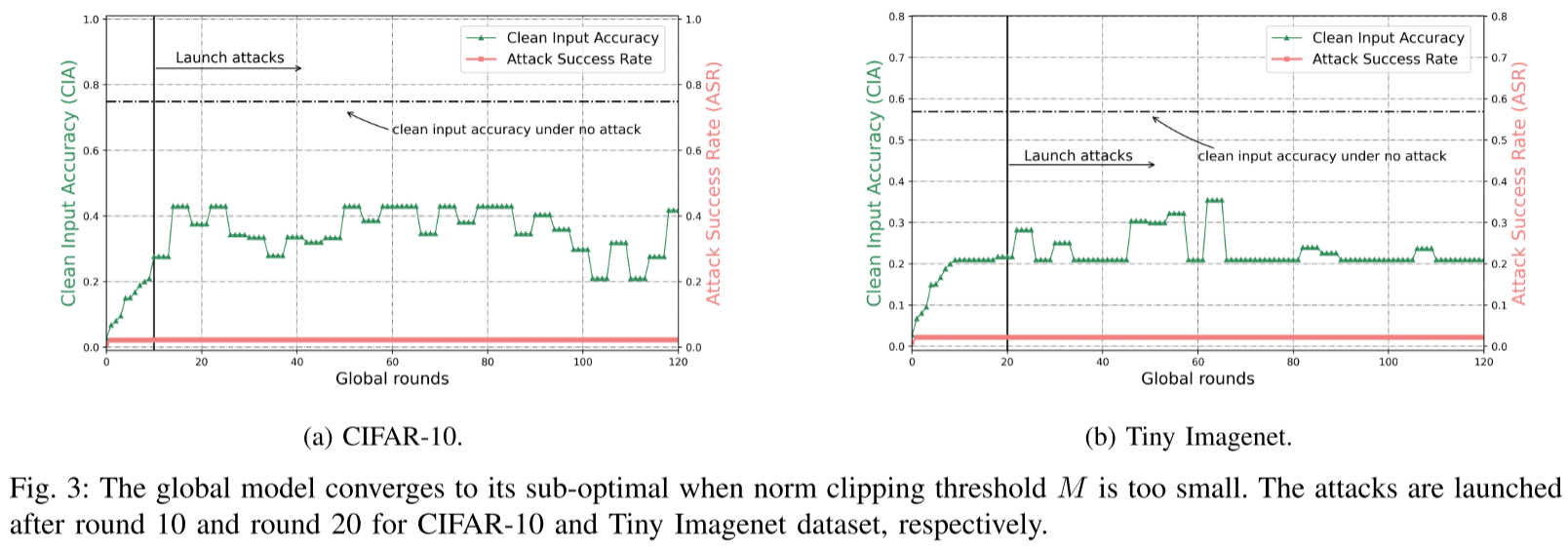
如果 M 设置得太小,例如比局部更新的平均范数小一个阶,即 $M=0.1\mathbb{E}_{i \in n}{||\Delta \omega_i^1||}_2$,虽然可以限制广泛的恶意更新,但它导致缓慢收敛到最优全局模型,或收敛到次优。
根据实验,当 M 增加到与局部更新的平均范数相同的数量级时,即 $M=\mathbb{E}_{i \in n}{||\Delta \omega_i^1||}_2$,高 CIA 和低 ASR 都可以满足。
通过简单地增加阈值 M 并在整个训练过程中保持某个 M 不变会带来另一个问题,也就是说,对手可以通过鲁棒训练绕过范数裁剪防御,该训练在每个全局回合中估计 M 足够接近。
方法:可以通过比较任何连续两轮中全局模型的大小来很好地估计它。
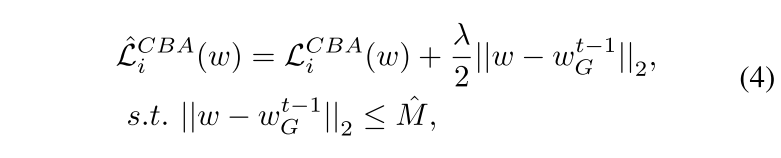
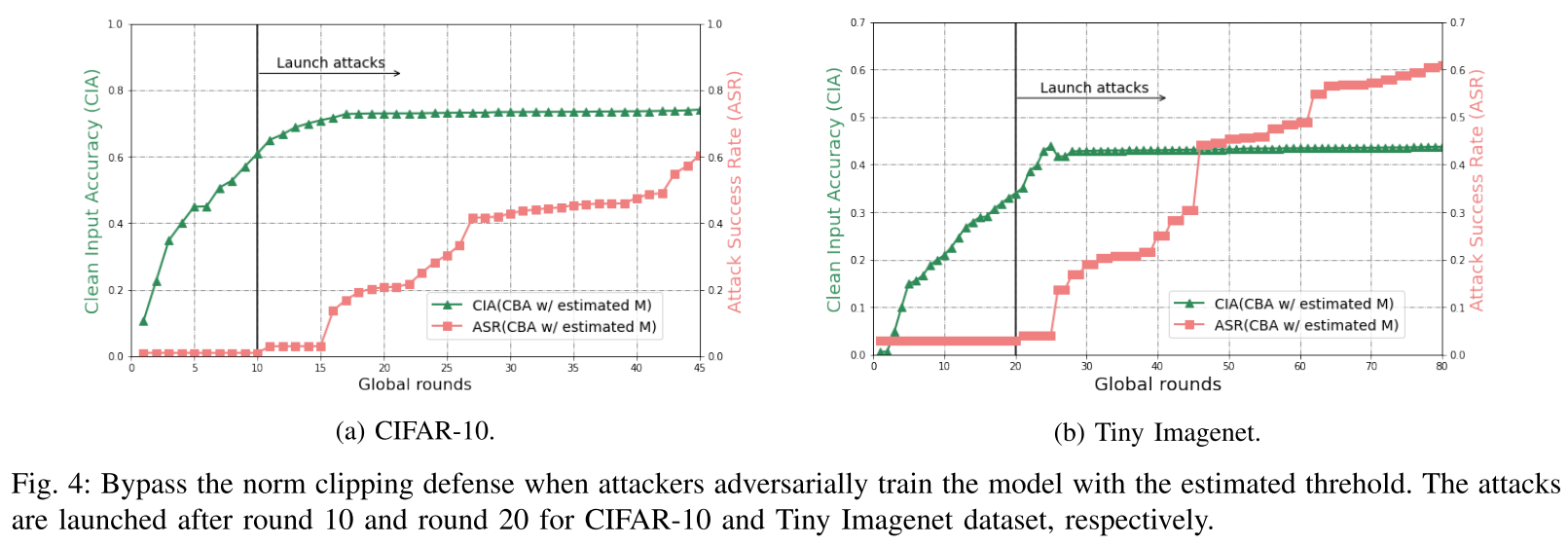
- 随着轮次 T 的增加,攻击成功率通常会增加,同时干净输入的准确性也会略有下降。
- 在发起攻击后,攻击成功率的增量存在“延迟”。
收敛时良性局部更新的动态性质
数裁剪方案失败的主要原因是其在训练过程中的固定阈值,无法捕捉到全局模型收敛过程中良性局部更新的动态特性。
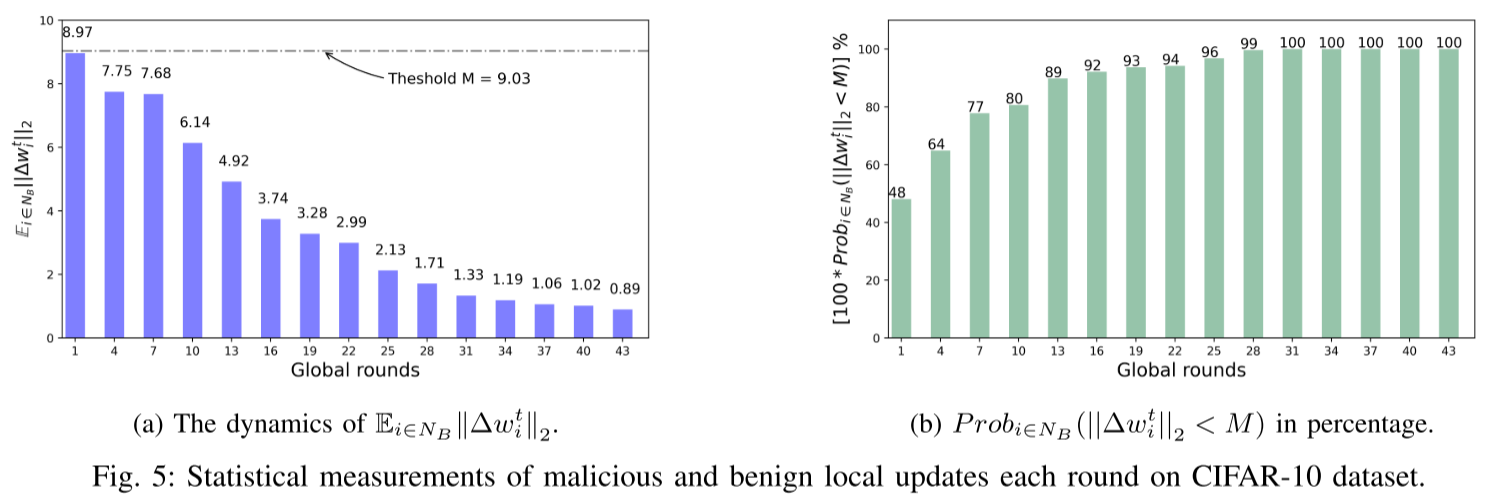
我们的解决方案:动态范数裁剪方法
防御者的能力:服务器扮演防御者的角色。服务器无法直接访问本地数据集。服务器还有一个单独的测试数据集用于性能评估。防御者不知道合谋攻击者之间的攻击策略。

百分位阈值 $\tau$ 的选择对于我们的防御效率和全局模型的收敛至关重要。
实验
- 数据集:MNIST、FMNIST、CIFAR-10 和 Tiny ImageNet
- 数据分布:no-iid
- 训练模型:LeNet-5 和 ResNet-18
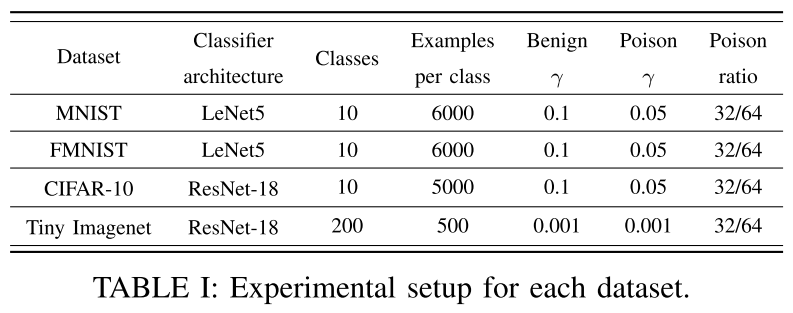

- 基线模型:FedAvg RFA FoolsGold 范数裁剪 SignSGD RLR
- 评估指标:攻击成功率(ASR)和干净输入准确率(CIA)
实验结果
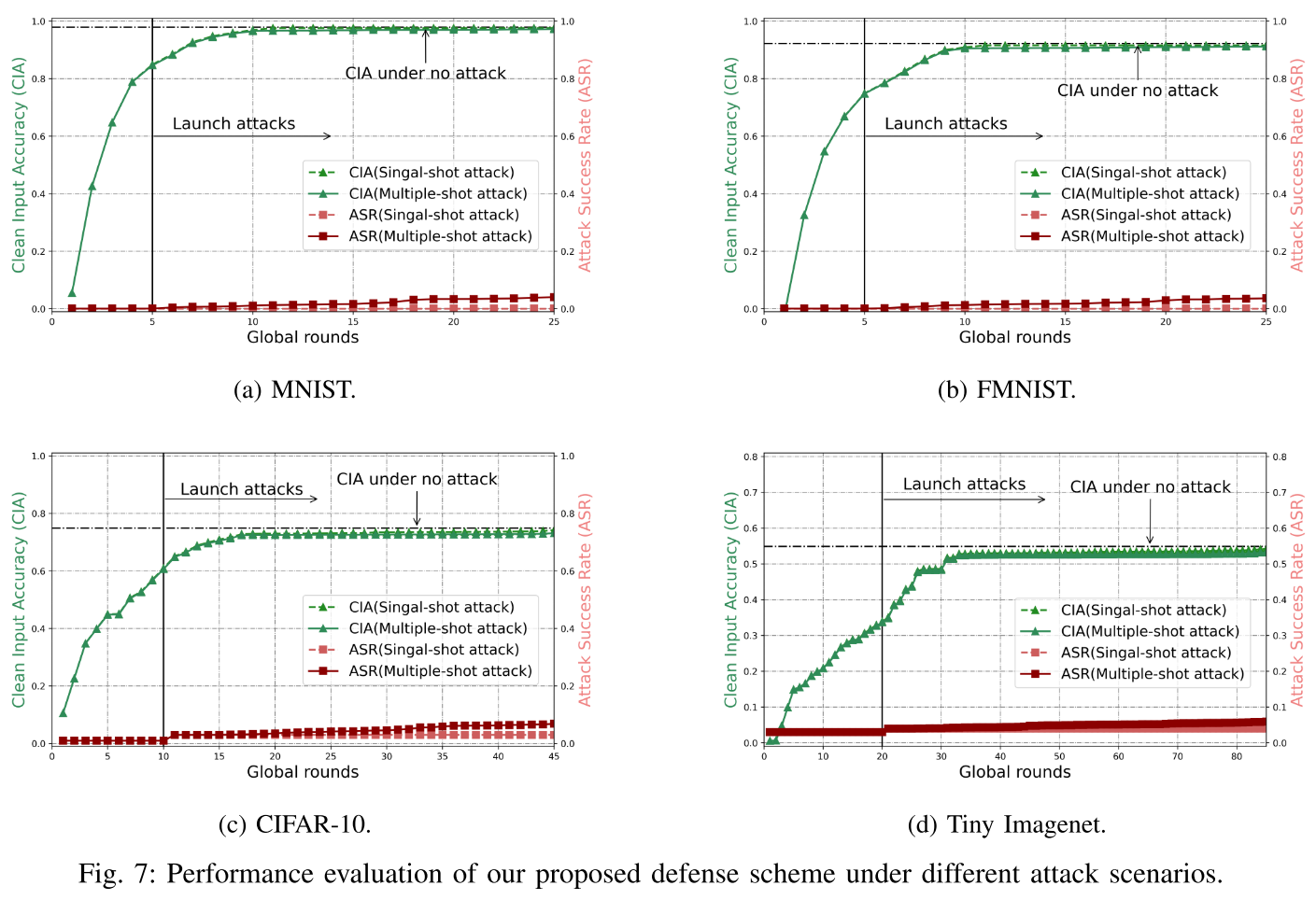
- 我们的防御迫使全局模型在测试数据集上很好地收敛,具有高干净输入精度和低攻击成功率。
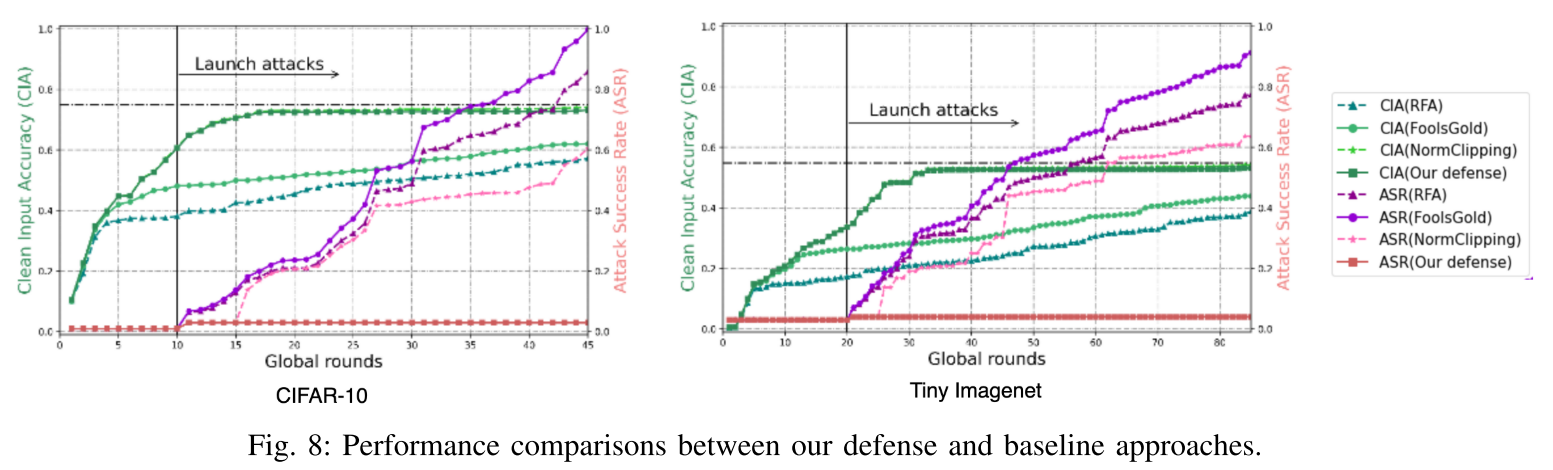
- 我们的防御在推动全局模型的收敛和降低攻击成功率方面优于现有的防御,特别是在后期。
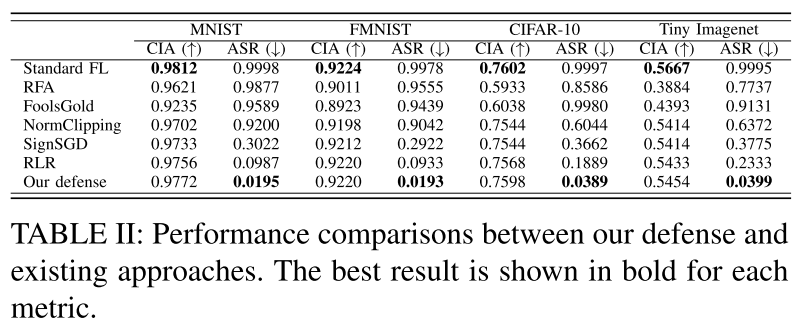
- 与标准 FL 相比,我们的防御在整体测试精度上的下降可以忽略不计,同时保持较低的攻击成功率。
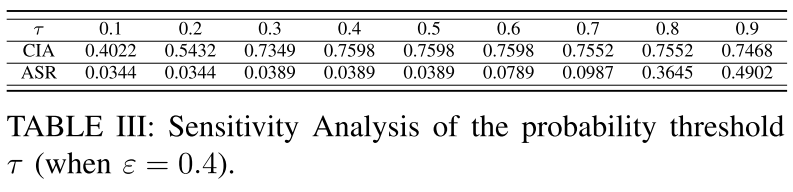
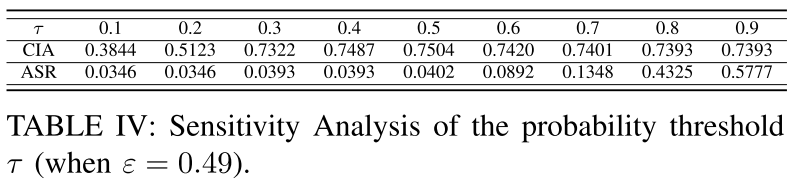
- 当
$\tau \in [0.3, 0.5]$时,同时满足高 CIA 和低 ASR。
总结
在本文中,作者提出了一种新颖的防御方案来抵抗 FL 中的分布式后门攻击。特别是,作者首先确定导致范数裁剪方案失败的主要原因是训练过程中的固定阈值,无法捕获全局模型收敛过程中良性局部更新的动态性质。然后,在此激励下,作者提出了一种新颖的防御措施,以动态调整本地更新的规范剪切阈值。作者还介绍了作者的防御方案的收敛性分析。通过在 non-IID 设置下对四个公共数据集进行实验,作者发现作者提出的防御可以有效地降低攻击成功率并保持高性能的效用。特别是,与现有防御相比,作者的防御平均降低了 84.23% 的攻击成功率。