| 论文英文名字 | A highly efficient, confidential, and continuous federated learning backdoor attack strategy |
|---|---|
| 论文中文名字 | 一种高效、隐蔽、持久的联邦学习后门攻击策略 |
| 作者 | Jiarui Cao, Liehuang Zhu |
| 来源 | 14th ICMLC 2022: Guangzhou, China |
| 年份 | 2022 年 3 月 |
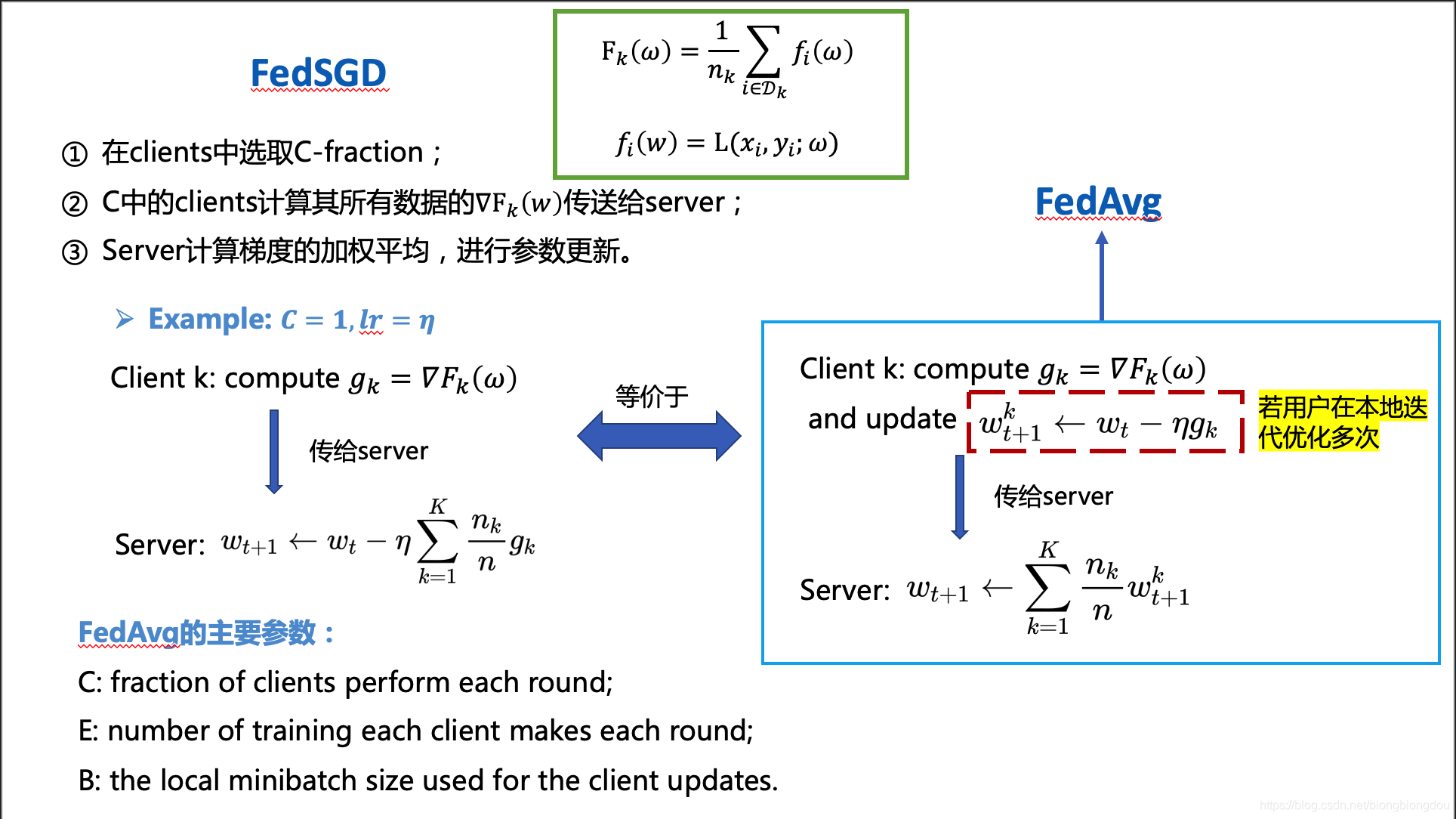
| 作者动机 | 在 FedSGD 和 no-iid 的设置下进行后门攻击 |
| 阅读动机 | |
| 创新点 | (1)通过攻击者的协商来征服 FoolsGold 防御;(2)改进的 FedSGD 后门攻击梯度上传策略(3)位木马方法来实现 no-iid 联邦学习的持久性 |
内容总结
主要贡献
- 提出了一种新的 no-iid 联邦学习后门攻击策略,在克服 no-iid 联邦学习防御时性能几乎不会下降。
- 提出了一种针对 FedSGD 后门攻击的改进梯度上传策略,在原始基础上显着提高了后门攻击的隐蔽性。
- 与其他后门攻击策略相比,我们的策略通过独特的模型中毒策略,具有很强的持久性。
预备知识
FedAVG
参与者上传的参数是通过本地训练生成的整个本地模型参数。
在 FedAVG 中,全局模型 G 在每次迭代 t 时更新如下:
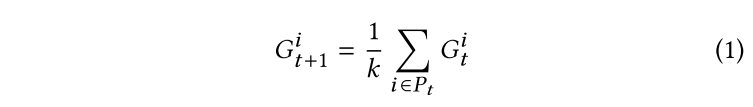
FedSGD
参与者上传的参数是在本地训练的随机梯度下降中产生的梯度数据。
在 FedSGD 中,全局模型 G 在每次迭代 t 时更新如下:
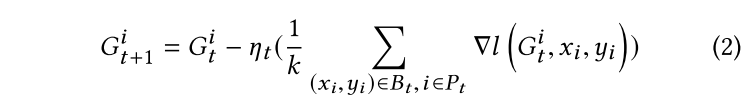
区别
FedSGD 和 no-iid 挑战
攻击方法:攻击者毒害他们自己的数据集来训练中毒的本地模型,并将他们的 $\nabla l(G_t^i,x_i,y_i)$ 上传到全局服务器以执行后门攻击。
问题:可以训练很好的中毒模型,但毒化全局模型有挑战。(2)
解决办法:增加攻击者数量
问题: 容易被 FoolsGold 防御(1)
方法:使用模型替换
问题:全局模型的主任务性能会瞬间降低,后门隐蔽性不足。(2)
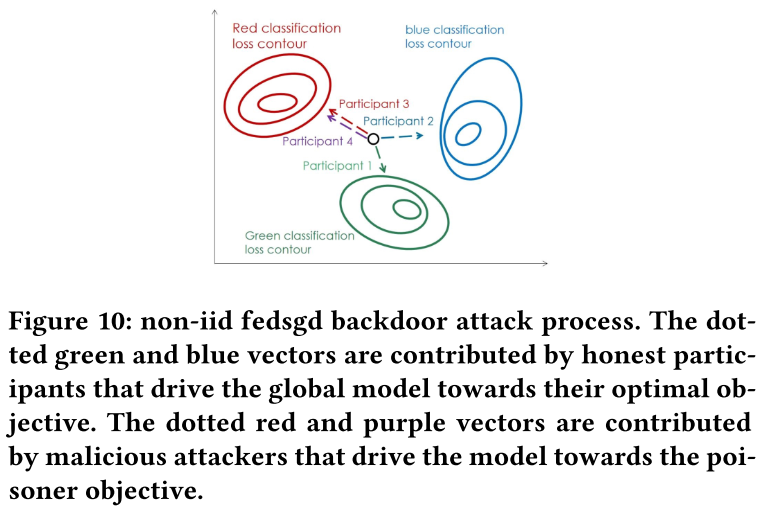
此外,在 no-iid 的联邦学习中,全局模型始终处于更广泛的更新状态。(3)
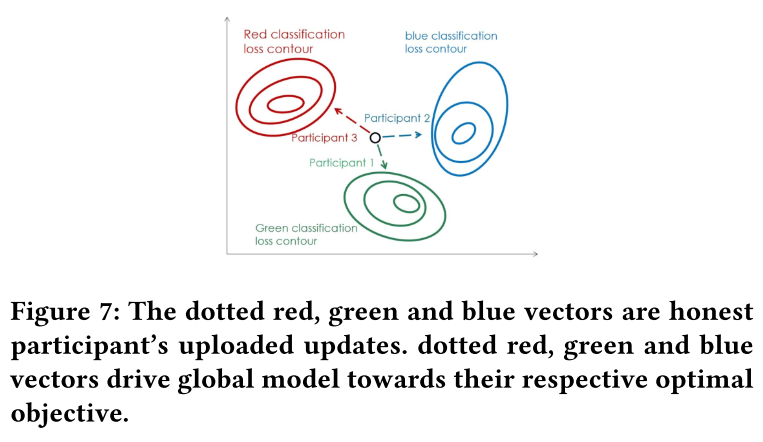
- FoolsGold 防御限制了联邦学习中恶意攻击者的数量。
- 全局模型总是处于剧烈更新状态,在这种情况下很难保留捕获图像的触发器的后门。
- 对于传统的 FedSGD 后门攻击,依靠梯度
$\nabla l(G_t^i,x_i,y_i)$来毒化全局模型是低效的。但是,采用模型替换策略不符合后门攻击的隐蔽要求。
后门攻击策略
安全假设
- 恶意攻击者可以相互协商。
- 恶意攻击者拥有服务器的测试数据集。他们可以通过下载的全局模型来估计服务器当前的准确性和损失值,以保证后门攻击的隐密性。
- 恶意攻击者需要了解全局模型的聚合规则,关注学习率和每轮训练的参与者数量。
后门攻击策略目标
- 我们的攻击策略可以在非独立同分布的联邦学习中保持持久性。
- 我们的攻击策略是高效的,只需要几个回合和几个攻击者就可以成功地在全局模型中植入一个后门。
- 我们的攻击策略是保密的。 当我们的攻击在全局模型中植入后门时,模型性能变化相对较低。
- 我们的攻击策略可以战胜 FoolsGold 防御。
提高后门攻击的持久性
- 减少修改的神经元节点数。我们只修改对目标分类影响最大的节点,以减少全局更新的影响。
- 放弃将特定的后门结构注入到模型中,并调整图像的触发器以适应模型的后门。通过这种方式,我们可以减少对特定后门结构的依赖。
首先找到连接到目标类 K 的神经元 $W_K$,然后通过神经梯度排序(NGR)策略来识别对目标输出影响最大的神经元。
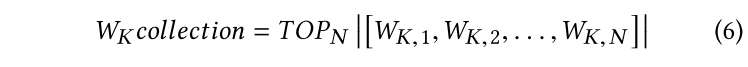
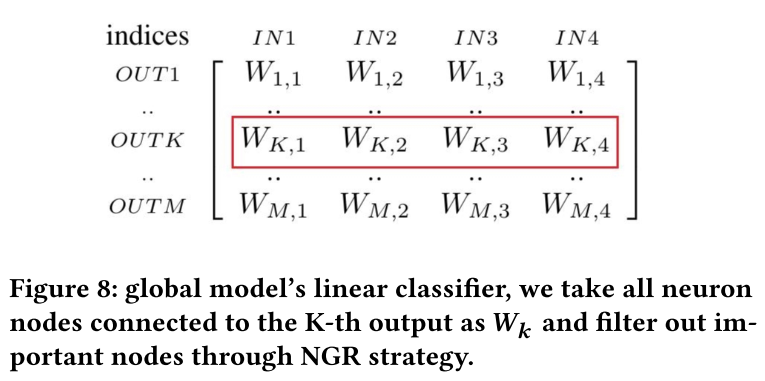
使用测试数据集测试全局模型,并使用 NGR 过滤出重要的神经元节点。 在随后的后门攻击中,只更新线性分类器中的重要神经元节点。

提高攻击效率和保密性
方法:渐进式模型替换
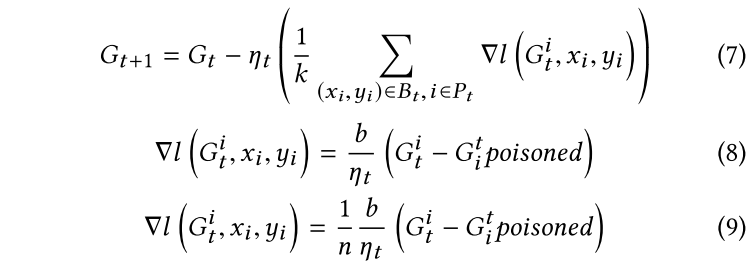
征服 FoolsGold 防御

实验
- 数据集:MNIST 和 CIFAR-10
- 数据分布:no-iid
- 训练模型:Resent-18
评估指标
- 联邦学习后门攻击的效率通过几轮攻击中是否只有几个攻击者就可以完成后门攻击来评估。
- 通过中毒测试集中全局模型的准确率下降率来评估联邦学习后门攻击的持久性。
- 当我们的攻击在全局模型中植入一个后门时,联邦学习后门攻击的隐蔽性通过纯测试集上的准确性变化来评估。要求突变相当低(不超过1%)。
实验结果
提出的攻击策略实验
在全局模型即将收敛时进行后门攻击实验,攻击从第 3 轮开始,攻击间隔为 2 次,总共进行 10 次攻击。
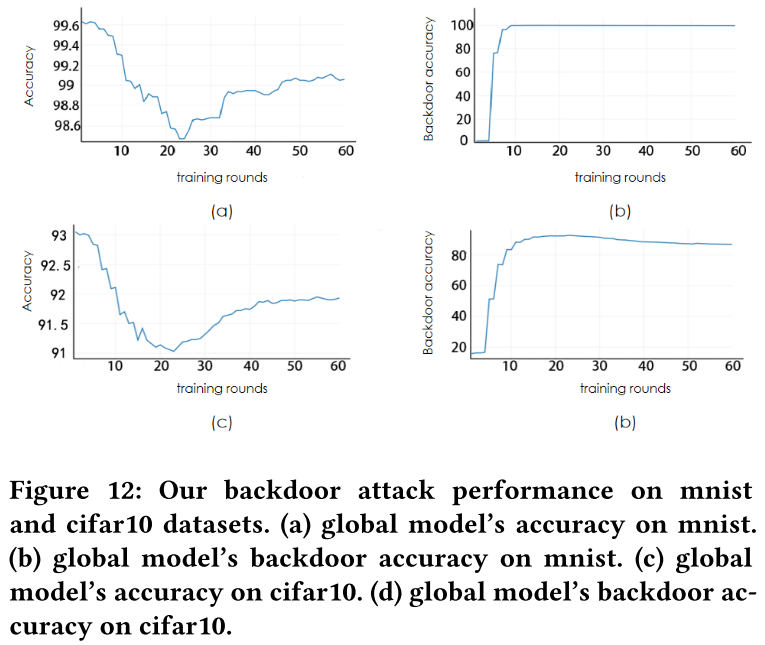
- 在 MNIST 数据集上 0.2% (99.4%-99.2%),在 CIFAR-10 数据集上 0.5% (92.2%-91.7%)。
- 在 MNIST 上没有性能下降,CIFAR-10 从 91% 下降到 81%。
模型替换对比实验
在全局模型即将收敛时进行后门攻击实验,攻击从第 10 轮开始,进行 1 次攻击。
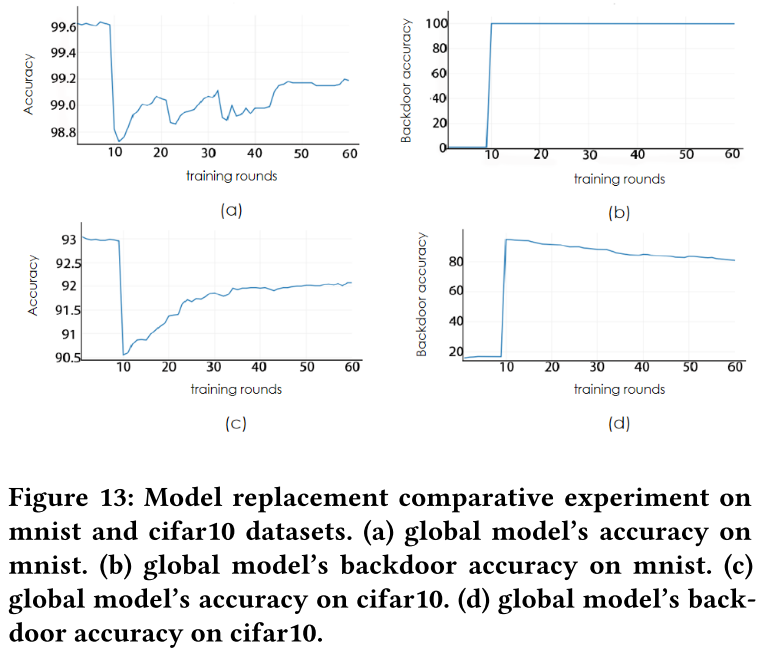
- 最大性能变化在 MNIST 上为 0.8%(99.6%-98.8%),在 CIFAR-10 上为 2.5%(93%-92.5%)。
- 我们的后门攻击的隐蔽性比模型替换策略有了很大的提高。
- 模型性能下降率没有大的差别。
- 与模型替换策略相比,我们的后门攻击策略在保证持久性的情况下实现了更好的隐蔽性。
后门攻击对比实验
与标签反转攻击进行对比
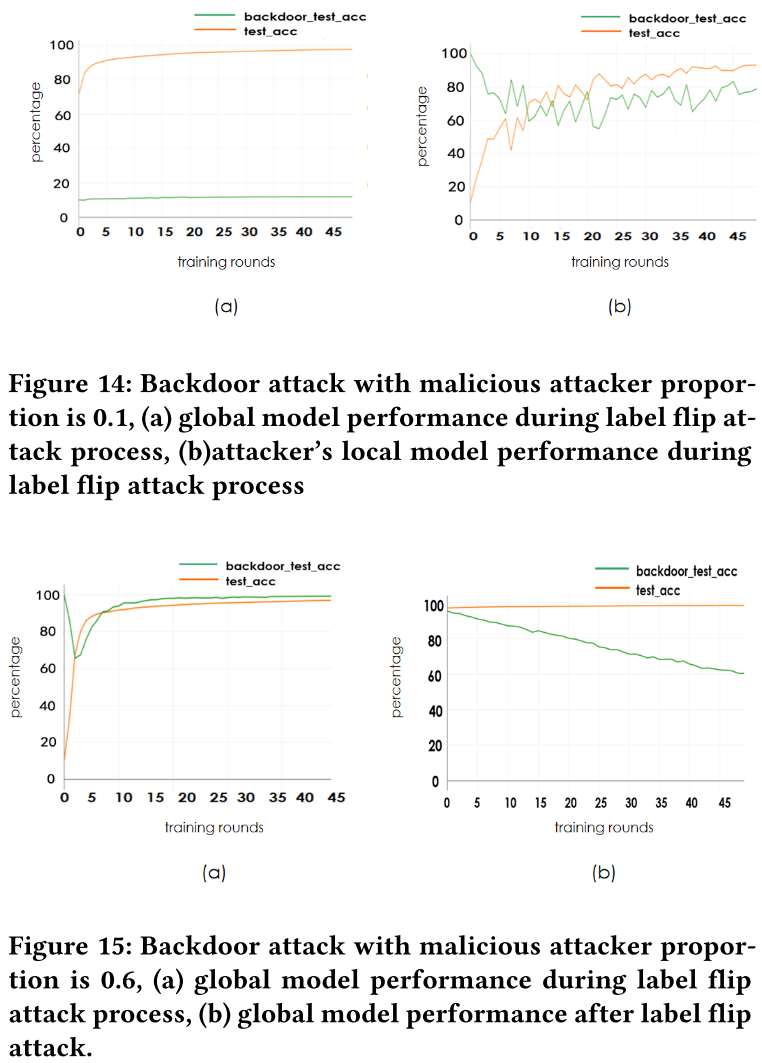
- 我们的攻击效率高于标签翻转攻击。
- 我们的攻击持久性高于标签翻转攻击。
FoolsGold 防御对比实验
关闭 FoolsGold 防御
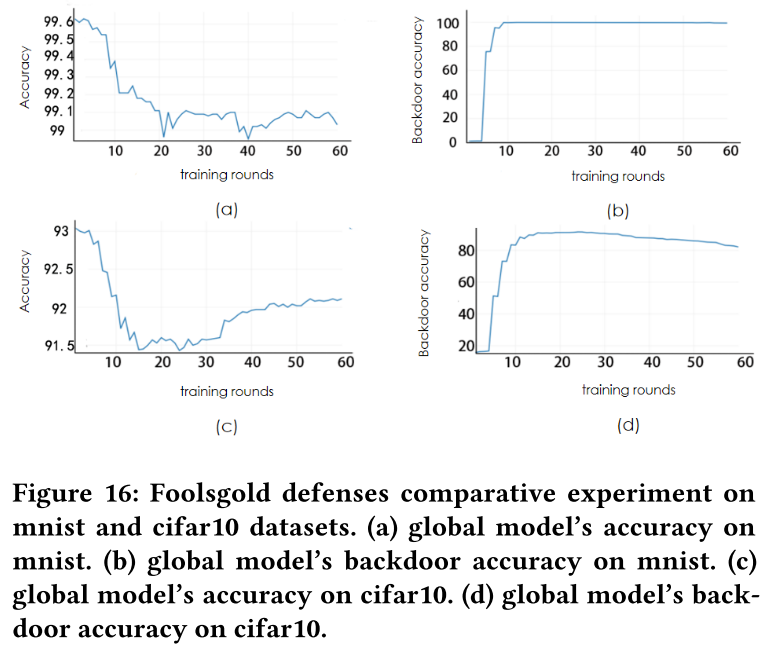
- MINST 最大性能变化为 0.15%(99.38%-99.23%),CIFAR-10的最大性能变化为 0.5%(92.2%-91.7%)
- FoolsGold 防御对我们的攻击性能几乎没有影响。
- 后门准确率曲线几乎没有任何区别。
结论
no-iid 联邦学习后门攻击的研究缺乏有效的研究。我们提出了一种新的 no-iid 联邦学习后门攻击策略。我们的后门攻击策略将联邦学习后门攻击过程分为两部分:局部中毒模型训练和中毒模型参数上传。对于局部中毒模型训练,我们通过比特木马攻击实现渐进式模型替换,对于中毒模型参数上传,我们通过攻击者协商降低相似度。我们对不同的数据集进行了广泛的实验,以说明我们的后门攻击策略在非联邦学习上是高效、隐蔽和持久的。我们将专注于提高我们算法的隐蔽性和持久性,以确保未来研究中的攻击效率。我们希望我们的工作能激发对 no-iid 联邦学习防御的进一步研究。