| 论文英文名字 | Against Backdoor Attacks In Federated Learning With Differential Privacy |
|---|---|
| 论文中文名字 | 在具有差分隐私的联邦学习中对抗后门攻击 |
| 作者 | Lu Miao, Wei Yang, Rong Hu, Lu Li, Liusheng Huang |
| 来源 | ICASSP 2022: Virtual and Singapore [CCF 计算机图形学与多媒体 B 类会议] |
| 年份 | 2022 年 5 月 |
| 作者动机 | 先前的工作表明,差分隐私(DP)可以用来防御后门攻击,但代价是模型效用的巨大损失。 |
| 阅读动机 | |
| 创新点 | 根据当前模型更新自适应地设置适当的阈值来限制恶意更新的范数 |
内容总结
主要贡献
- 提出了一种在 DP 防御后门攻击时保持主要任务高精度的方法。
- 针对两种后门攻击实施 CND 的方法:单像素攻击和语义后门攻击。
具有裁剪范数衰减的差分隐私
威胁模型
服务器是诚实的,并且攻击者控制了一部分客户端,称为恶意(中毒)客户端。
目标:在主任务和后门任务上都具有高精度。
假设语义后门攻击中的敌手可以修改中毒客户端的训练数据,并像模型中毒攻击一样操纵训练过程,这是对敌手能力的强假设。
假设单像素攻击中的恶意客户端仅修改其数据集中的后门样本的标签,如数据中毒攻击。
算法
方法:随着训练的进行降低 DP 中模型更新的裁剪阈值。

- 在训练开始之前初始化一个限幅范数阈值
$c_0$,并在每一轮将该阈值与全局模型一起发送给选定的客户端。 - 客户端将在每批计算其局部模型更新,并且如果更新的范数超过阈值
$c_0$,则使用阈值$c_0$来裁剪更新。 - 随着轮数的增加,服务器将把阈值减小到新的值
$c_t$,并在后面的轮次中将其发送给所选择的客户端。
其中我们使用 Moments Account 来计算每轮开始时花费的隐私预算,并在每轮结束后累积隐私损失。

直觉:随着轮数的增加,模型更新的范数逐渐减少。
原因如下:(1)损失的减少导致梯度的减小;(2)学习率逐渐衰减。
较小的裁剪阈值意味着较少的噪声注入和较高的模型精度。因此,我们建议随着训练的进行降低限幅阈值。
服务器首先将阈值乘以衰减系数作为默认值,然后计算每个客户端更新的平均范数。
如果平均范数小于默认值,服务器会将其设置为新的阈值。由于模型更新在上传之前被裁剪,平均范数不会大于当前阈值。这一步的目的是使阈值自适应下降。
如果初始阈值太大,平均范数会远低于默认值,因此阈值会迅速降低。因此,如果初始阈值较小,大多数更新将被裁剪,裁剪阈值将缓慢下降。
裁剪阈值在前几轮后落在合理范围内,之后只需要每隔一定的时间进行调整即可。
平均范数也受到干扰,以免泄露隐私,但噪音的规模可与算法 1 不同。
实验
- 数据集:CIFAR-10 和 EMNIST
- 数据分布:Non-IID
- 模型:ResNet18 和 具有两个卷积层、一个最大池化层和两个密集层的五层 CNN
实验结果
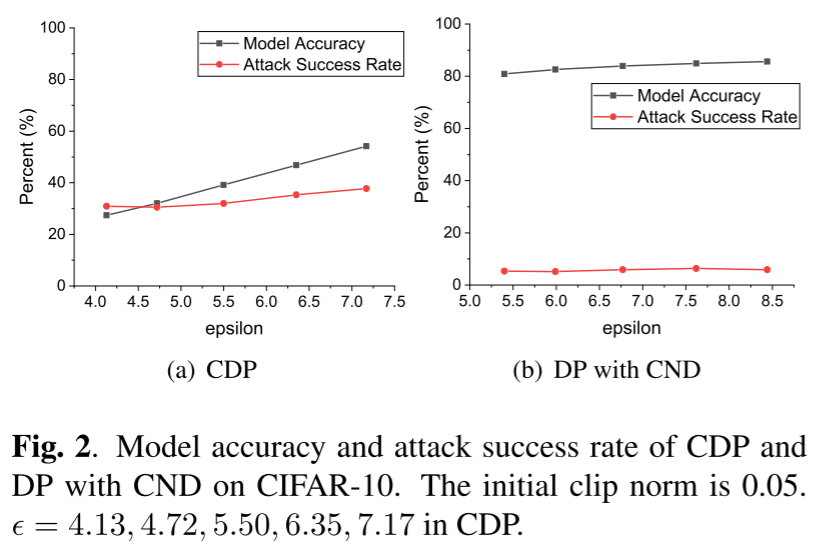
- 就通过 DP 添加的噪声幅度而言,防御效率和数据效用之间存在权衡。
- 对于 CDP 来说,增加更多的噪声有助于降低后门攻击的成功率,但也大大降低了模型的准确性。
- 在带有 CND 的 DP 的情况下,扰动的增加不会导致模型精度明显下降。
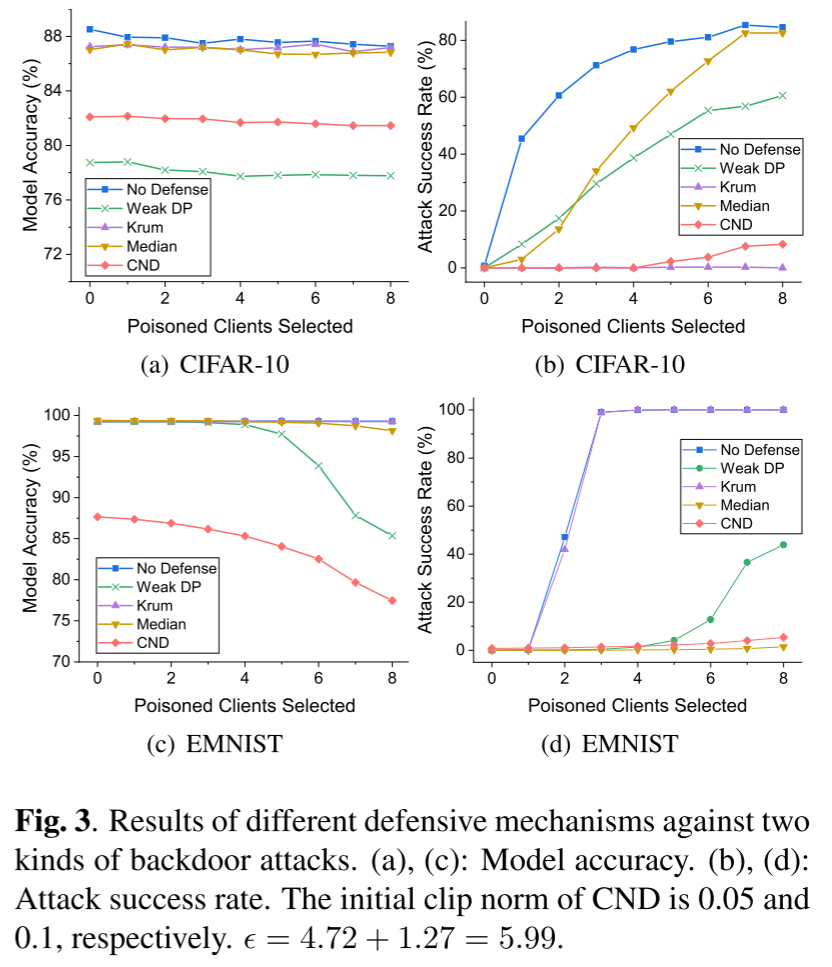
- 我们的方法提供了针对两种后门攻击的通用防御,将成功率降低到接近于零。
总结
针对后门攻击导致模型效用损失的问题,提出了一种基于动态规划的防御方法,降低了训练过程中模型更新的裁剪阈值。通过自适应地设置合适的阈值,我们的算法减少了噪声注入并消除了恶意更新的影响。CND 的实验表明,与原始 DP 相比,该方法不仅提高了主任务的准确率,而且进一步降低了后门攻击的成功率。与最先进的防御机制相比,CND 的性能远远超过它们。