| 论文英文名字 | FLAME: Taming Backdoors in Federated Learning |
|---|---|
| 论文中文名字 | 在联邦学习中驯服后门 |
| 作者 | Thien Duc Nguyen, Phillip Rieger, Hossein Yalame, Helen Möllering, Hossein Fereidooni, Samuel Marchal, Markus Miettinen, Azalia Mirhoseini, Ahmad-Reza Sadeghi, Thomas Schneider, Shaza Zeitouni |
| 来源 | 31th USENIX Security Symposium 2022 [CCF 网络与信息安全 A 类会议] |
| 年份 | 2022 年 8 月 |
| 作者动机 | 基于检测和过滤恶意模型更新的后门攻击防御只考虑非常特定和有限的攻击者模型,而基于差分隐私激励的噪声注入的防御显著恶化了聚合模型的良性性能。 |
| 阅读动机 | 经典阅读 |
| 创新点 | 估计注入的足够噪音量,以确保消除后门。为了最小化所需的噪声量,使用了模型聚类和权重裁剪的方法。 |
内容总结
预备知识
HDBSCAN
HDBSCAN 是一种基于密度的聚类算法,它利用 n 维空间中数据点的距离将彼此靠近的数据点组合成一个簇。 因此,集群的数量是动态确定的。不适合任何集群的数据点被视为异常值。
虽然 HDBSCAN 的前身 DBSCAN 使用预定义的最大距离来确定两个点是否属于同一个集群,但 HDBSCAN 根据点的密度独立确定每个集群的最大距离。因此,在 HDBSCAN 中,最大距离和聚类总数都不需要预先定义。
差分隐私
DP 是一种隐私技术,旨在确保输出不会泄露参与者的个人数据记录。DP 的正式定义如下:

其中 $\varepsilon$ 表示隐私界限,$\delta$ 表示打破这个界限的概率。较小的 $\varepsilon$ 和 $\delta$ 值表示更强的隐私。
实现差分隐私的一种常用方法是向算法输出中添加随机高斯噪声 $N(0, \sigma^2)$
威胁模型
对手的目标
同时保证主任务和后门任务的准确率。(不被聚合器识别)
对手的能力
- 假设对手
$\mathcal{A}$完全控$k<\frac{n}{2}$个客户端及其训练数据、过程和参数。 $\mathcal{A}$完全了解聚合器的操作,包括潜在应用的后门防御。$\mathcal{A}$无法控制在聚合器和诚实的客户端上执行的任何进程。
问题设置和目标
后门表征
每个模型 $W_i$ 可以用两个因素来表征:其权重向量 $(w^1,w^2,...,w^p)$ 的方向(角度)和大小(长度)
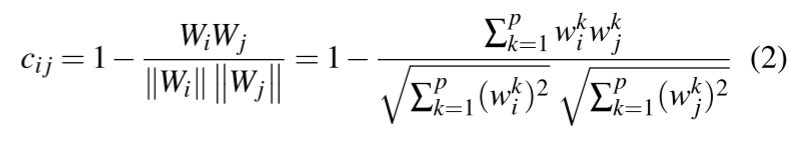
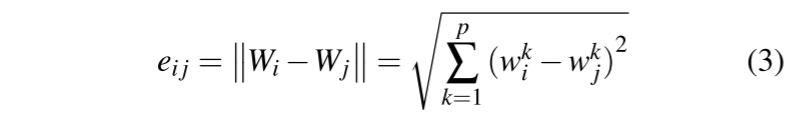
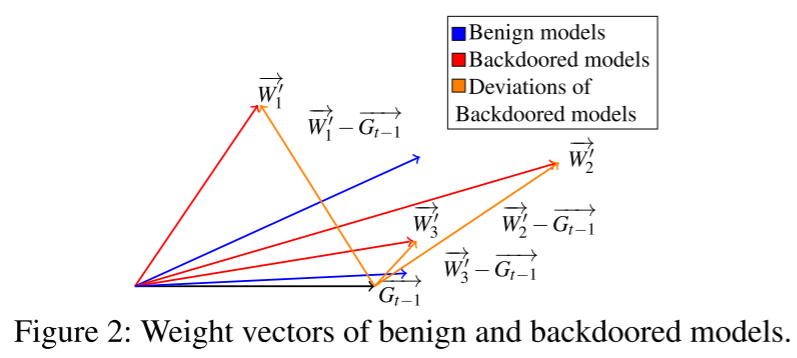
敌对目标(注入后门)的影响会导致模型参数出现偏差,表现为后门模型权重向量的方向和/或幅度与良性模型相比存在差异。
防御目标
- 有效性:为了防止对手实现其攻击目标,必须消除后门模型更新的影响,以便聚合的全局模型不会显示后门行为。
- 性能:必须保持全局模型的良性性能,以保持其效用。
- 独立于数据分布和攻击策略:防御方法必须适用于一般的对手模型,即它不得要求事先了解后门攻击的方法,或对本地客户端的特定数据分布进行假设,例如,数据是 iid 还是 non-iid。
FLAME 概述和设计
高级想法
- 动机:早期工作使用聚合模型的差分隐私启发噪声来消除后门。它们根据经验确定要使用的足够的噪声量。然而,在 FL 设置中,这是具有挑战性的,因为通常不能假设聚合器能够访问训练数据,特别是中毒的数据集。因此,需要一种通用方法来确定多少噪声足以有效地消除后门。另一方面,模型中注入的噪声越多,其良性性能受到的冲击就越大。
- FLAME 概述:FLAME 估计在 FL 设置中移除后门所需的噪声级,而无需广泛的经验评估和访问训练数据。此外,为了有效地限制所需的噪声量,FLAME 使用一种新颖的基于聚类的方法来识别和删除具有高影响的对抗性模型更新,并应用动态权重裁剪方法来限制对抗性模型的影响,这些模型按比例放大以提高其性能。
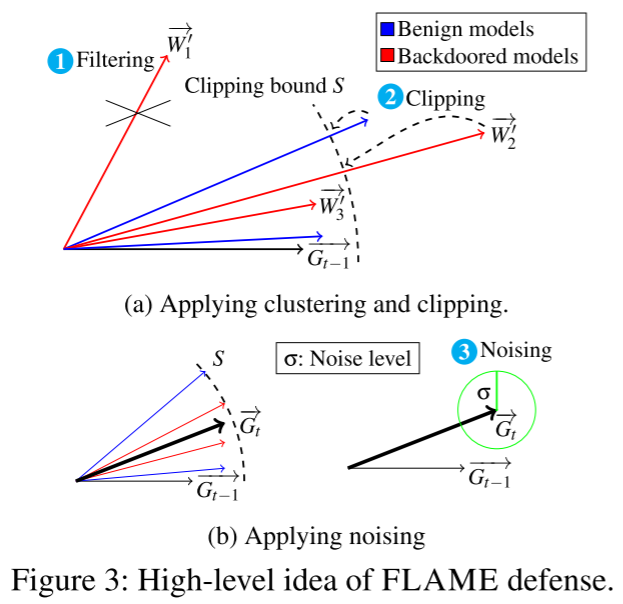
设计挑战
- 过滤掉动态场景中角度偏差较大的逆向模型
- 与现有的基于集群的防御相比,我们需要一种也可以在动态攻击设置中工作的方法,即注入后门的数量是未知的,并且可能在训练轮次之间变化。
- 使用固定数量的集群
$n_{cluster}$来识别恶意模型的集群方法天生容易受到不同数量的后门$n_{backdoor}$的攻击。这是因为对手通过同时注入n_{backdoor} \geq $n_{cluster}$后门,由于鸽子洞原理,可能导致至少一个后门模型与良性模型聚集在一起。我们试图通过采用集群解决方案来解决这一挑战,该解决方案动态地确定用于模型更新的集群,从而允许其适应动态攻击。
- 限制扩大后门的影响
- 通过按比例缩小权重向量,将幅度超过裁剪界限 S 的所有模型(特别是后门模型
$W_2^{'}$)的权重向量裁剪到 S - 如何选择适当的裁剪边界,而不凭经验评估其对训练数据集(在FL设置中不可用)的影响?
- 通过按比例缩小权重向量,将幅度超过裁剪界限 S 的所有模型(特别是后门模型
- 为后门消除选择合适的噪声级
- FLAME 使用模型噪声,该模型噪声应用具有噪声水平
$\sigma$的高斯噪声,以减轻后门模型的对抗性影响。 - 必须仔细选择噪声水平
$\sigma$,因为它对防御的有效性和模型的良性性能有直接影响。
- FLAME 使用模型噪声,该模型噪声应用具有噪声水平
FLAME 设计
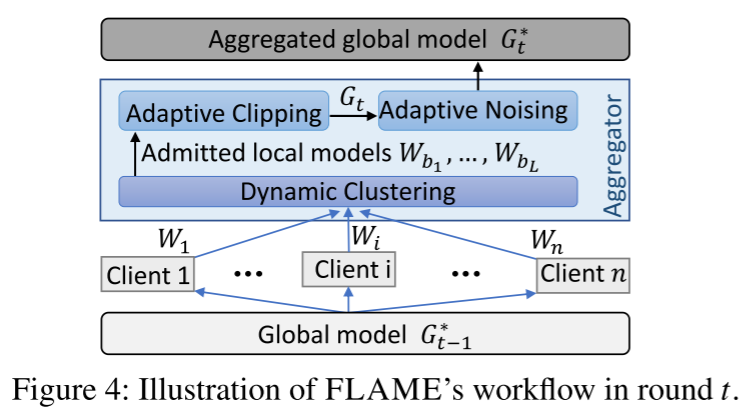

- 动态模型过滤
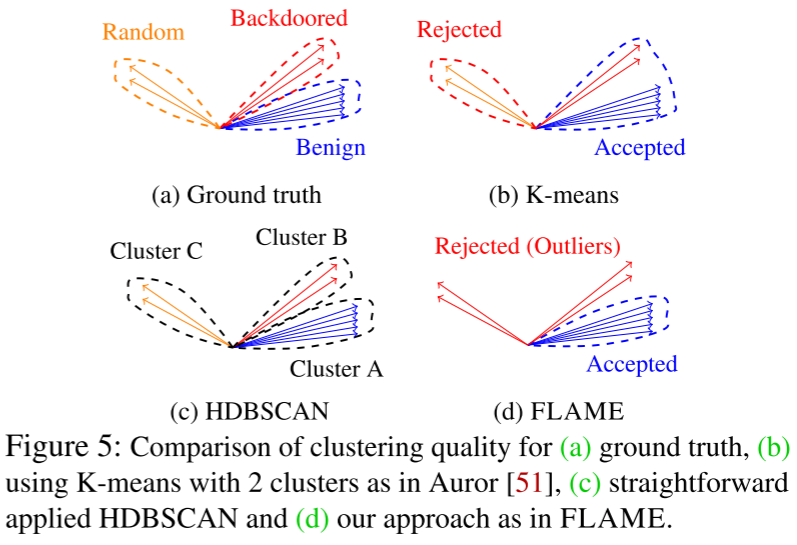
现有聚类方法的不足:现有的方法不能防止攻击者 $\mathcal{A}$ 通过使用不同的客户端组注入不同的后门来同时注入多个后门的攻击。
聚类目标:(1)它能够处理同时注入多个后门的动态攻击场景,(2)它最大限度地减少中毒模型识别的误报。
方法:FLAME 使用成对余弦距离来测量所有模型更新之间的角度差,并应用 HDBSCAN 聚类算法。
- 自适应剪裁和去噪
自适应裁剪
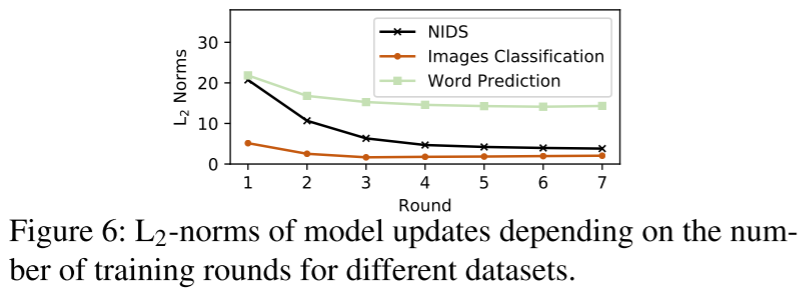
良性模型更新的 L2 范数在后面的训练轮次中变得更小。
为了有效地去除后门,同时尽量减少对良性更新的影响,裁剪界 $S$ 需要动态适应 L2 范数的这种下降趋势。
计算所有 n 个模型更新的 L2 范数的中值:$S_t = MEDIAN(e_1,...,e_n)$作为裁剪边界 $S_t$。
注意:为了确定剪裁界限,还考虑了被拒绝的模型,以确保即使过滤了良性模型,计算的中值 $S_t$ 仍然是基于良性值确定的。
自适应噪声
通过向模型权重中添加噪声,可以有效缓解异常样本的影响。
挑战:确定尽可能小的噪声级,以消除后门,同时不恶化模型的良性性能。
方法:噪声量是通过基于局部模型之间的差异(距离)估计灵敏度来确定的,这可以在不访问训练数据的情况下完成。
安全分析
FLAME 的噪声边界检验

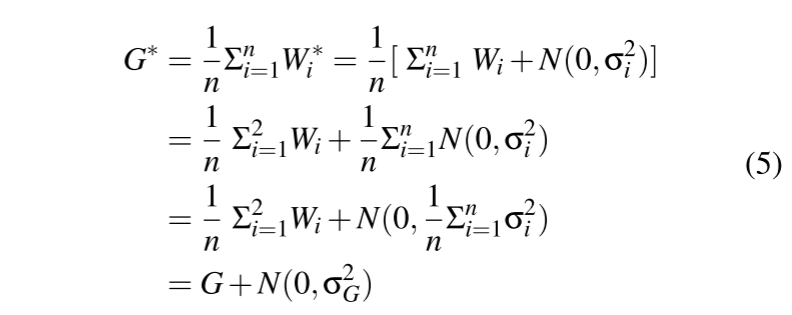
全局模型上的等效高斯噪声是应用于每个局部模型的高斯噪声的总和。
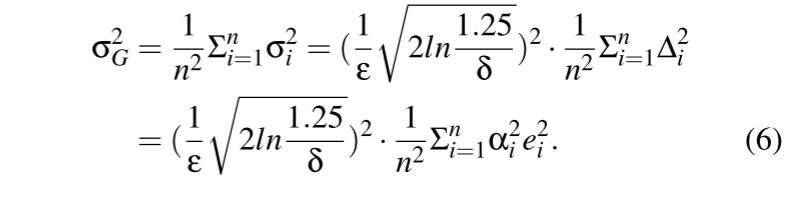
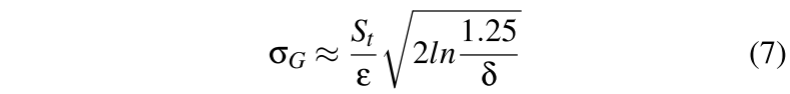

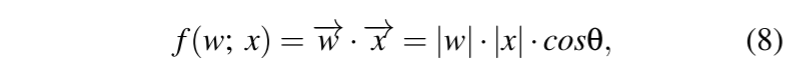
攻击和数据分布假设
不对攻击和数据分布做出具体假设。
FLAME 被配置为使得群集组件仅移除具有高攻击影响的模型而不是所有恶意模型,即其旨在移除如 图 3 所示的第一后门类型 $W_1^{'}$。此外,FLAME 仔细估计了裁剪边界和噪声水平,以确保在保留模型性能的同时消除后门。
实验
- 数据集:word prediction, image classification and an IoT intrusion detection
- 评估指标:BA - Backdoor Accuracy, MA - Main Task Accuracy, TPR - True Positive Rate and TNR - True Negative Rate
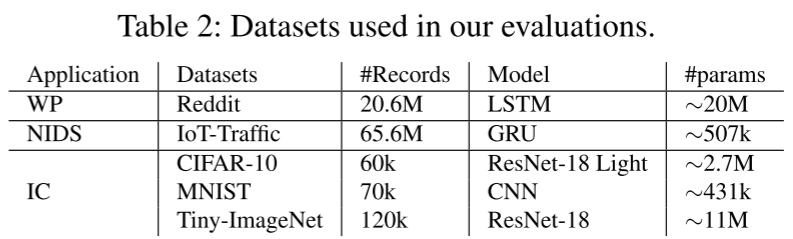
实验结果
- 防止后门攻击
FLAME 的有效性
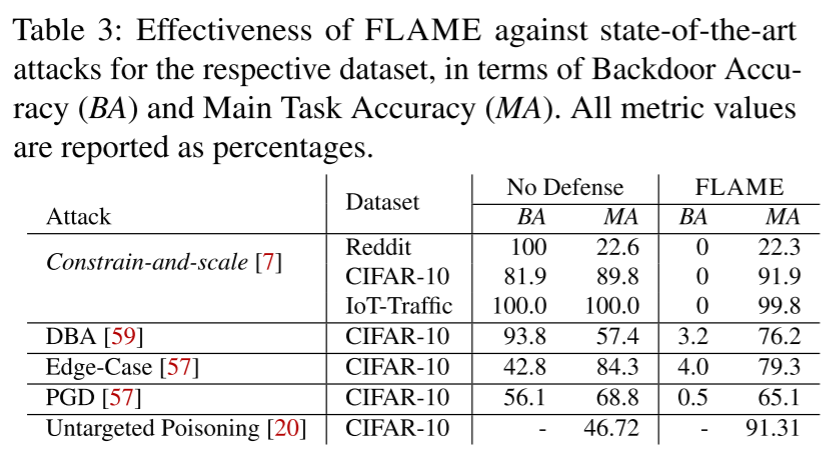
- FLAME 完全缓解了所有数据集的后门攻击。此外,我们的防御不会影响系统的主任务准确性(MA)。
与现有防御的比较
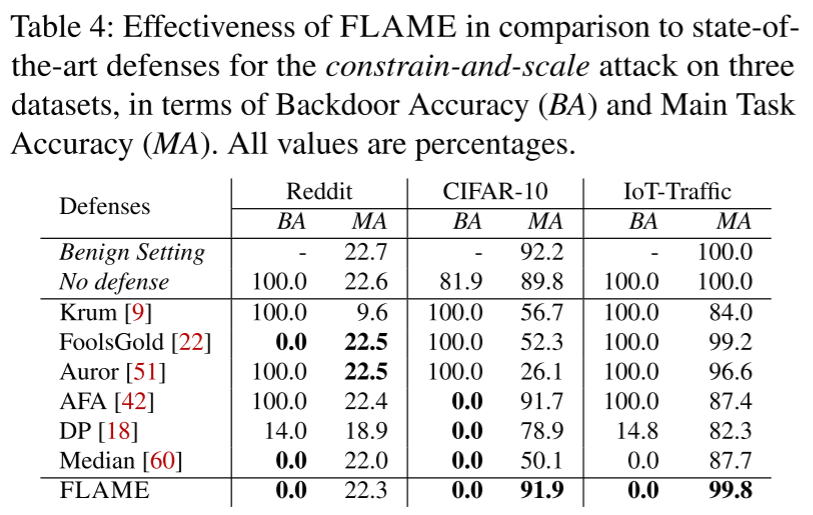
- FLAME 对所有 3 个数据集都有效,而之前的工作要么无法缓解后门,要么降低了主要任务的准确性。
对自适应攻击的弹性
- 改变注入策略
攻击者 $\mathcal{A}$ 可能会尝试同时注入多个后门,以对系统并行执行不同的攻击或规避集群防御。
(1)为恶意客户端分配不同的后门;(2)让每个恶意客户端注入多个后门。
- 模型对齐
每个恶意客户端被分配随机数量的恶意数据,即范围从 5% 到 20% 的随机 PDR。
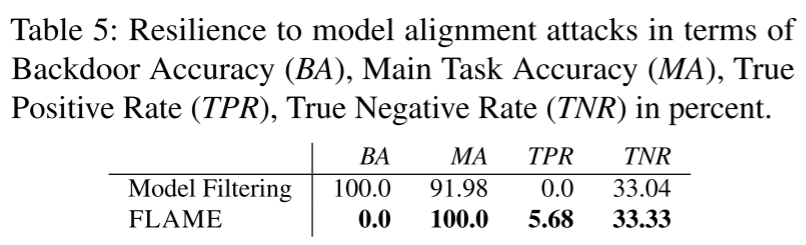
- 模型混淆
$\mathcal{A}$ 可能会给中毒模型添加噪声,使其难以检测。
客户端数量的影响
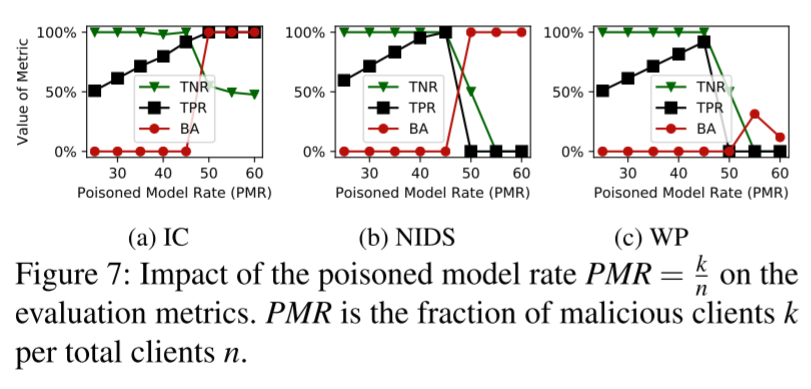
- FLAME 仅在 PMR < 50% 时有效,因此只有良性客户端被允许进入模型聚合(TNR = 100%),因此 BA = 0%。
- 然而,如果 PMR > 50%,FLAME 不能减轻攻击,因为大多数中毒模型将被包括在内,导致低 TNR。
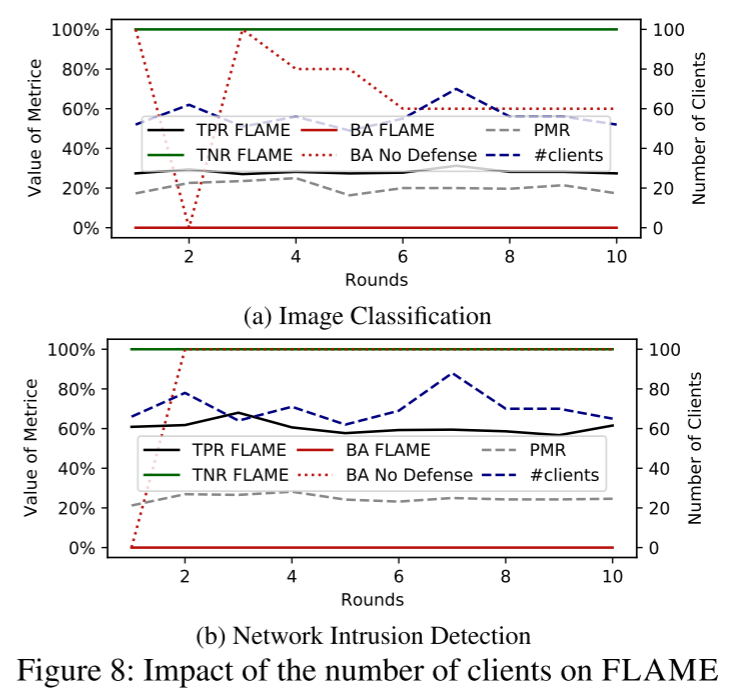
- 恶意客户端(PMR)的比例并不影响 FLAME 的有效性,即在每一轮中后门被完全移除(BA = 0%)。
non-iid 数据维度的影响
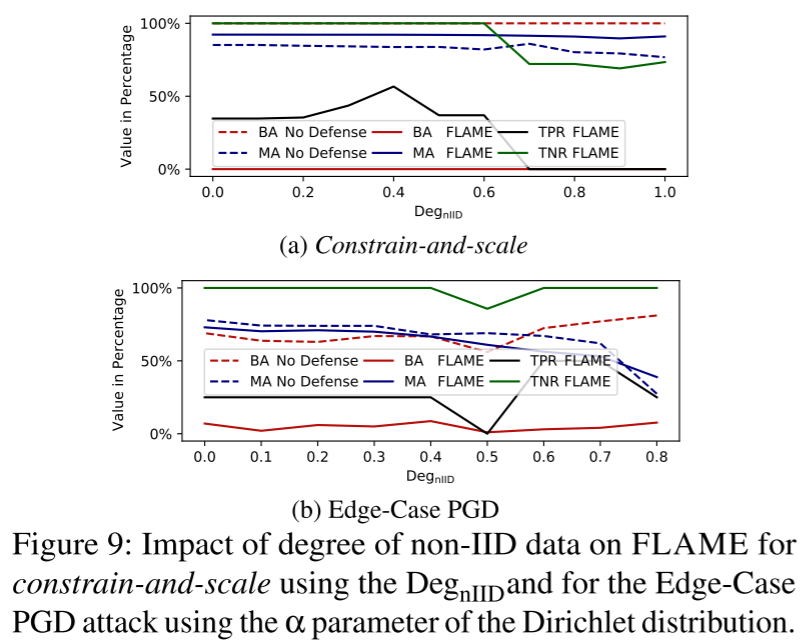
FLAME 有效地减轻了后门攻击。
总结
在本文中,我们介绍了 FLAME,一个用于 FL 的弹性聚合框架,它消除了后门攻击的影响,同时保持了聚合模型对主要任务的性能。我们提出了一种方法来近似需要注入到全局模型中以中和后门的噪声量。此外,结合我们的动态聚类和自适应裁剪,FLAME 可以显著降低后门删除的噪声规模,从而保持全局模型的良性性能。此外,我们为 FLAME 设计、实现并测试了高效安全的两方计算协议,以确保客户端训练数据的隐私性,并阻止对客户端更新的推理攻击。
另一篇同内容论文:Flguard: Secure and private federated learning
参考
问题
- 差分隐私怎么防御后门攻击?