| 论文英文名字 | BaFFLe: Backdoor Detection via Feedback-based Federated Learning |
|---|---|
| 论文中文名字 | 基于反馈的联邦学习的后门检测 |
| 作者 | Sébastien Andreina, Giorgia Azzurra Marson, Helen Möllering |
| 来源 | 41st ICDCS 2021: Washington DC, USA [CCF 计算机体系结构/并行与分布计算/存储系统 B 类会议] |
| 年份 | 2021 年 7 月 |
| 作者动机 | 现有的缓解 FL 中毒攻击解决方案要么被自适应攻击所规避,要么忽视了客户端的隐私,要么需要对现有的 FL 算法进行大量的计算修改。寻求一种不会破坏客户数据隐私并且与标准 FL 算法完全兼容的防御 |
| 阅读动机 | |
| 创新点 | 利用参与 FL 过程的众多客户来改进一项任务,否则这项任务由单个实体执行是次优的。 |
内容总结
威胁模型
- 攻击者控制参与 FL 过程的多个客户端,并且这些客户端可以任意偏离 FL 协议(即,它们是拜占庭的)。
- 我们假设在每次训练迭代中,大多数客户都是诚实的:在所选的
$n$个客户中,多达$n_M$可能是恶意的,其中$n_M < \frac{n}{2}$。
反馈回路
概述
困难:保护机器学习免受后门攻击是一项具有挑战性的任务
原因:攻击者对机器学习系统的了解与防御者对攻击者的了解之间的不对称性。(只有攻击者知道的后门可以被明确地选择来逃避检测)
直觉:我们的目标是通过识别 FL 的一个特定特征来打破攻击者和防御者知识之间的这种不对称性,该特性可以帮助防御后门攻击:客户端的私有数据集的可用性,这些数据集共同提供了一组丰富多样的标记数据集。
解决方法:在 FL 过程中添加一个验证阶段,以便在每次迭代中,均匀随机选择一组客户机,验证上一轮获得的全局模型。当客户提供关于全局模型的“反馈”时,我们通过反馈循环来引用这个过程。
效果:隐式地扩大和丰富验证集,从而增加发现不当行为的机会。
挑战:恶意客户端可以通过将干净的模型声明为可疑来发起拒绝服务攻击,或者通过将中毒的模型标记为干净来增加攻击者的隐蔽性。
解决办法:仔细调整客户的投票权。
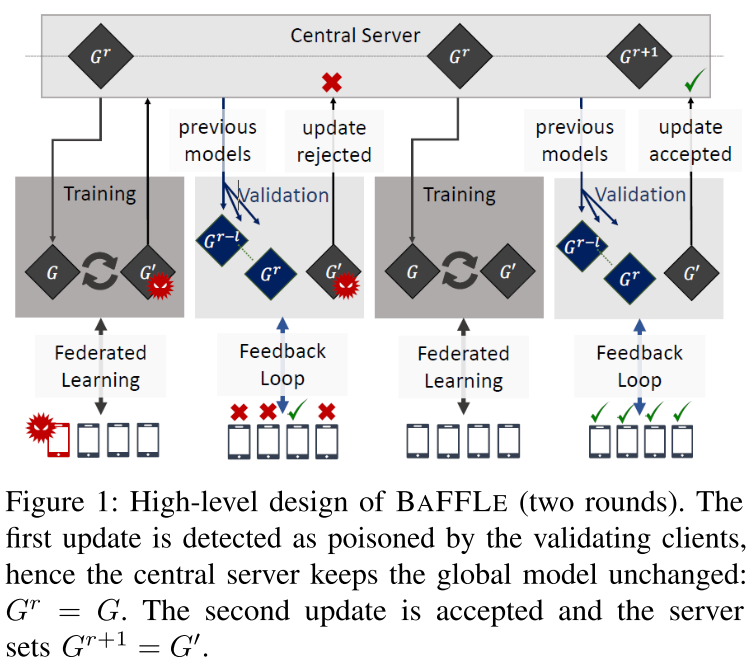
设计

- 获得用户局部更新,聚合得到当前待检测的全局模型。服务器获取
$n$个用户的更新,聚合后得到当前的全局模型$G^r$。 - 确定仲裁阈值
$q$使得是服务器拒绝当前全局模型需要的报告可疑的客户端的最少数量。既要保证不能因为恶意客户端的恶意误报而导致拒绝真正的模型(即$n_M < q$),也要保证能让诚实的客户端拒绝中毒模型(即$n_M < n-q$),其中$n_M$为恶意客户端的最大数量。当然考虑到诚实客户端也会有误判的情况,所以还要依据经验考虑到误判率$\rho$。 - 选择客户端。服务器随机选择
$n$个客户端,将当前的全局模型以及拒绝阈值发送给客户端。 - 客户端使用本地数据集进行验证。客户端验证全局模型,并根据拒绝阈值向服务器报告当前全局模型是否可疑。
- 服务器判断全局模型是否为中毒模型。如果有大于等于仲裁阈值
$q$的验证客户端认为该模型可疑,则服务器拒绝接受这一轮的全局更新,并令这一轮的全局模型为上一轮的全局模型$G^{r-1}$,继续进行下一轮的更新。
模型验证(检测语义后门)
直觉
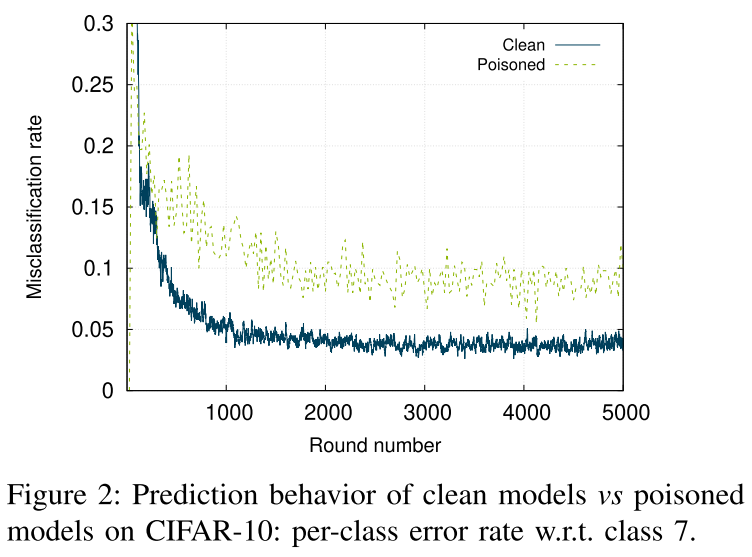
我们提出了一种直接的验证方法来比较当前模型 $G$ 与最近的先前接受的模型$\mathcal{G}^0,...,\mathcal{G}^\ell$(被认为是“干净的”)的分类性能。 我们的实例化依赖于以类别方式观察模型的预测行为。直观地说,我们预计诚实更新不会显着影响后续轮次中全局模型的每类错误率。相反,新注入的后门可能会提高一个或几个类的错误率。
误差变化的定义
- source-focused error:
$err_D(f)^{y\rightarrow x}$(将类 y 预测错误为其他类) - target-focused error:
$err_D(f)^{x\rightarrow y}$(将其他类错误预测为类 y) - 定义了两个模型之间的 wrong-prediction gap
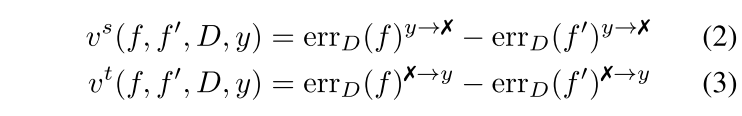
$\mathbf{v} = [\mathbf{v}^s,\mathbf{v}^t]$- 局部离群值因子(LOF)
- 通过检测一个点与邻居的接近度和邻居自身的接近度来检测数据集中的离群值
$LOF_k(x;N)$
设计

当且仅当当前变化 $\mathbf{v}_r$ 在 LOF 的意义上足够接近从已接受模型的历史中获得的相应值时,模型$G^r$才被接受。
实验
- 数据集:CIFAR-10 和 FEMNIST
- 数据分布:Non-IID
- 训练模型:ResNet18 CNN 模型
- 攻击策略:由单个客户端操作的模型替换攻击和标签反转
- 防御配置:仅服务器(BAFFLE-S)、仅客户端(BAFFLE-C)和两者(BAFFLE)
- 评估方法
$\ell = 10,20,30$$3≤q≤9$- C-S%
- (1)全局模型 G 已经稳定(精度在 90% 以上,在 10000 次完整的 FL 后达到),(2)G 未接近收敛,并且在早期几轮中启用了验证方法。
结果
回顾窗口大小的选择($\ell$)

- 使用反馈回路(BaFFLe-C 和 BaFFLe)的所有配置都产生了良好的检测率,即 0.0 和 0.1 之间的低 FN 率。
- 反馈回路(BaFFLe-C 和 BaFFLe)明显优于仅服务器配置(BaFFLe-S)。
- 基于此结果,我们因此设置
$\ell = 20$,因为该值产生 BaFFLe 最接近相等的错误率。
群体阈值的选择($q$)
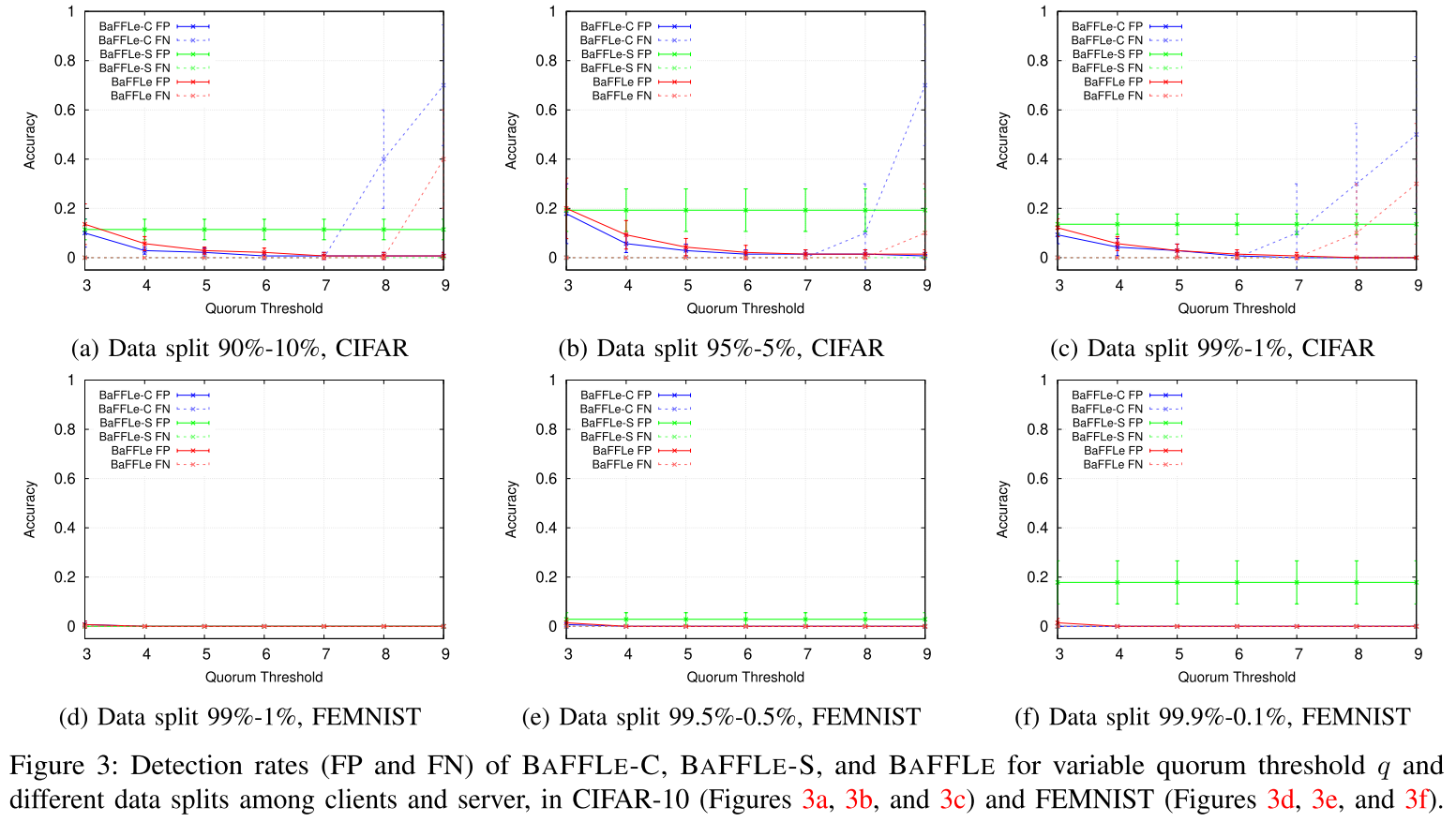
- 降低 q 会提高 FN 率
- 选择
$5≤q≤7$似乎是一个安全的选择,因为它产生了高检测精度和几乎相等的错误率。
在早期回合中启用检测
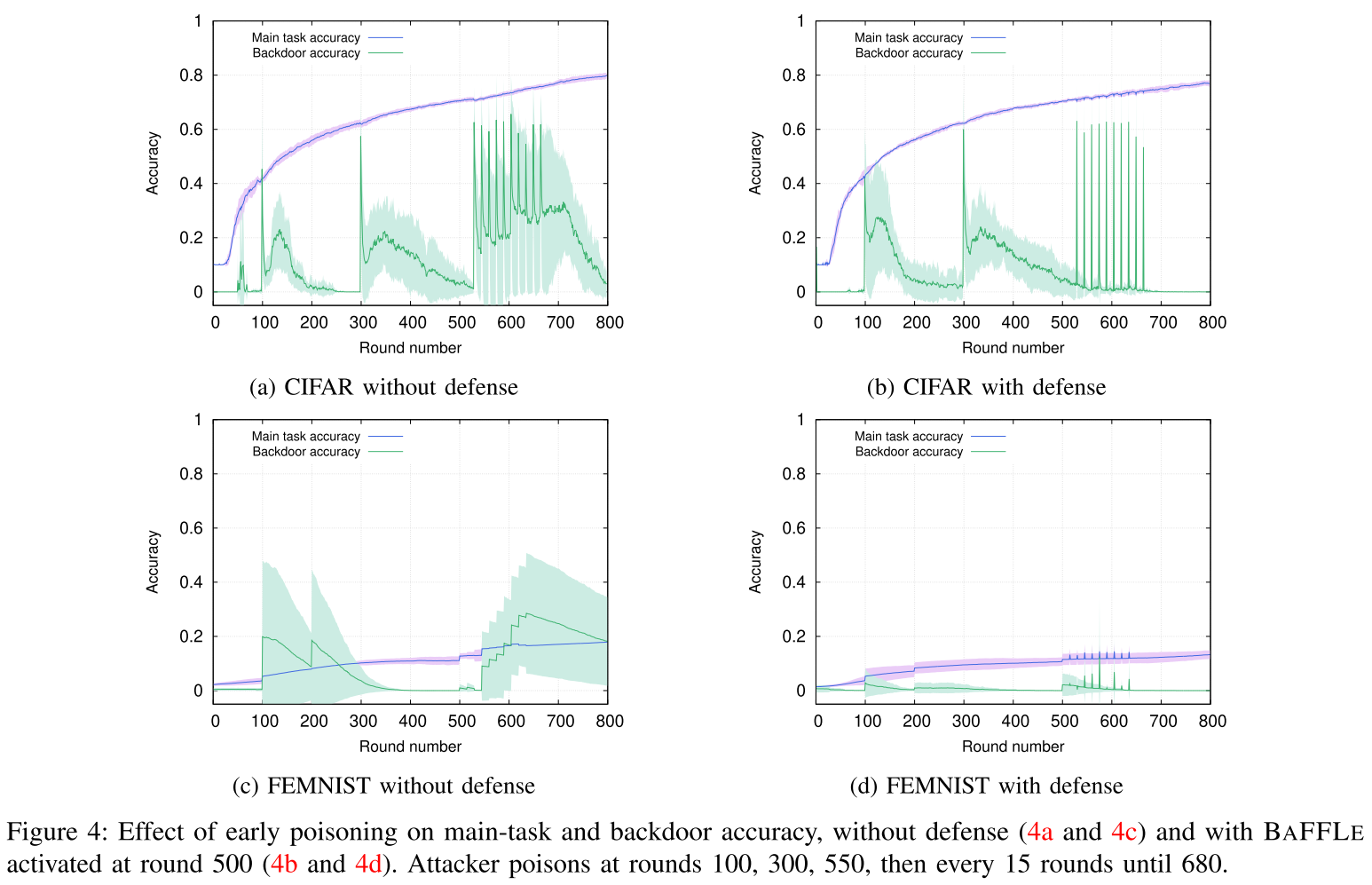
- 在早期回合(100和300)中注入的后门不耐用
- BaFFLe 成功地检测到在第 530 轮之后进行的几乎所有中毒尝试
自适应攻击
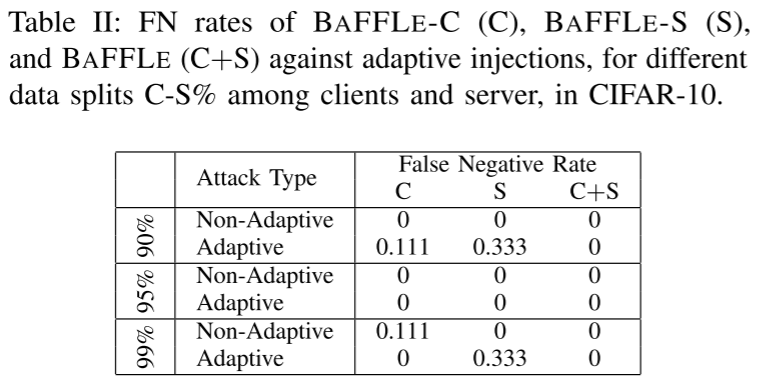
- 95% 到 100% 的自适应注入被 BaFFLe 检测到
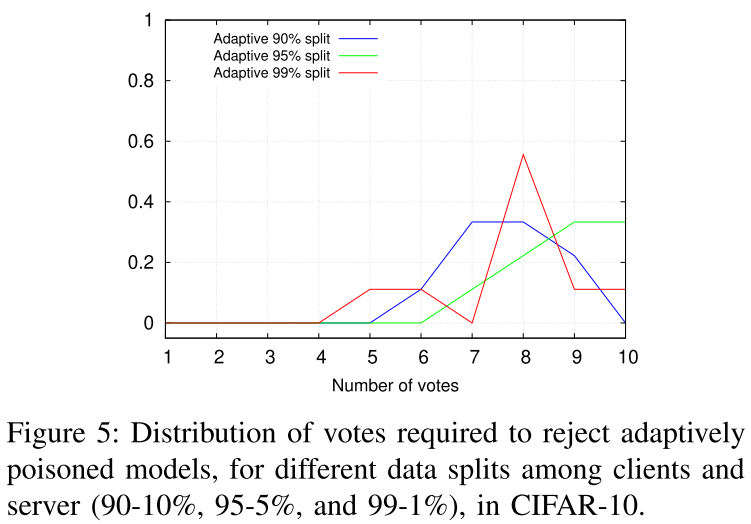
- 在最坏的情况下,最多有 5 个客户提供了错误的模型评估,即
$\rho=0.5$
通信开销
- 将贡献客户端设置为与验证客户端一致
- 节省客户端和服务器之间的一轮交互
- 允许客户端在每轮开始时立即开始本地训练,而不是等待其他客户端的判决
- 使用模型压缩技术
总结
我们的工作解决了保护FL免受后门攻击的问题,同时确保遵守安全聚合。我们提出了 BaFFLe,这是一个基于圆形的反馈回路,让客户参与验证全局模型。据我们所知,BaFFLe 是第一个对现有 FL 部署的修改最少针对后门攻击的 FL 防御,并通过确保与更新的安全聚合完全兼容,有效支持客户端数据的隐私。
参考
问题
- 客户端互相验证