| 论文英文名字 | Data Poisoning Attacks Against Federated Learning Systems |
|---|---|
| 论文中文名字 | 针对联邦学习系统的数据中毒攻击 |
| 作者 | Vale Tolpegin, Stacey Truex, Mehmet Emre Gursoy, Ling Liu |
| 来源 | 25th ESORICS 2020: Guildford, UK - Part I [CCF 网络与信息安全 B 类会议] |
| 年份 | 2020 年 9 月 |
| 作者动机 | 对联邦学习进行数据中毒攻击 |
| 阅读动机 | 了解联邦学习数据中毒攻击 |
| 创新点 | 分析数据中毒攻击并提出防御方法 |
内容总结
主要贡献
- 研究了 FL 系统对试图毒害全局训练模型的恶意参与者的脆弱性。(数据中毒攻击)
- 使用两个流行的图像分类数据集:CIFAR-10 和 Fashion-MNIST 来演示 FL 数据中毒攻击。
- 证明了攻击有效性(模型效用的减少)取决于恶意用户的百分比,即使这个百分比很小,攻击也是有效的。
- 证明了攻击是有针对性的,即它们对受到攻击的类子集有很大的负面影响,但对其余类几乎没有影响。
- 评估了攻击时机的影响(在前几轮或后几轮 FL 训练中中毒)和恶意参与者可用性的影响(恶意参与者是否可以提高其可用性和选择率以提高有效性)。
- 为 FL 聚合器提出了一种防御策略。
威胁和对手模型
威胁模型
- 将所有参与者
$P$中恶意参与者的百分比表示为$m\%$。 - 恶意参与者可以通过添加对手控制的设备、损害
$m\%$的良性参与者的设备或激励(贿赂)$m\%$的良性参与者来注入到系统中从而在一定数量的 FL 轮中毒害全局模型。 - 聚合器是诚实的,不会妥协。
对抗性目标
操纵学习到的参数,使得最终的全局模型 $M$ 对于特定类别($C$ 的子集)具有高误差。
对手知识和能力
每个恶意参与者可以在他们自己的设备上操纵训练数据 $D_i$,但是不能访问或操纵其他参与者的数据或模型学习过程,
联邦学习中的标签反转攻击
我们使用标签翻转攻击在 FL 中实现目标数据中毒。给定 $C$ 中的源类 $c_{src}$ 和目标类 $c_{target}$,每个恶意参与者 $P_i$ 修改其数据集 $D_i$ 如下:对于 $D_i$ 中类为 $c_{src}$ 的所有实例,将其类更改为 $c_{target}$。我们记为 $c_{src} \rightarrow c_{target}$。
评估指标
- 全局模型精度:
$\frac{TP+TN}{TP+TN+FP+FN}$ - 类召回:
$\frac{TP}{TP+FN}$ - 基线错误分类数:在基线中被错误分类的样本数量。
联邦学习中标签翻转攻击分析
- 数据集:CIFAR-10 和 Fashion-MNIST
- 数据分布:IID
- 训练模型:具有六个卷积层、批量标准化和两个全连接密集层的卷积神经网络和具有批量标准化的两层卷积神经网络
- 标签反转设置:(1)容易(2)困难(3)两者之间
标签翻转攻击可行性
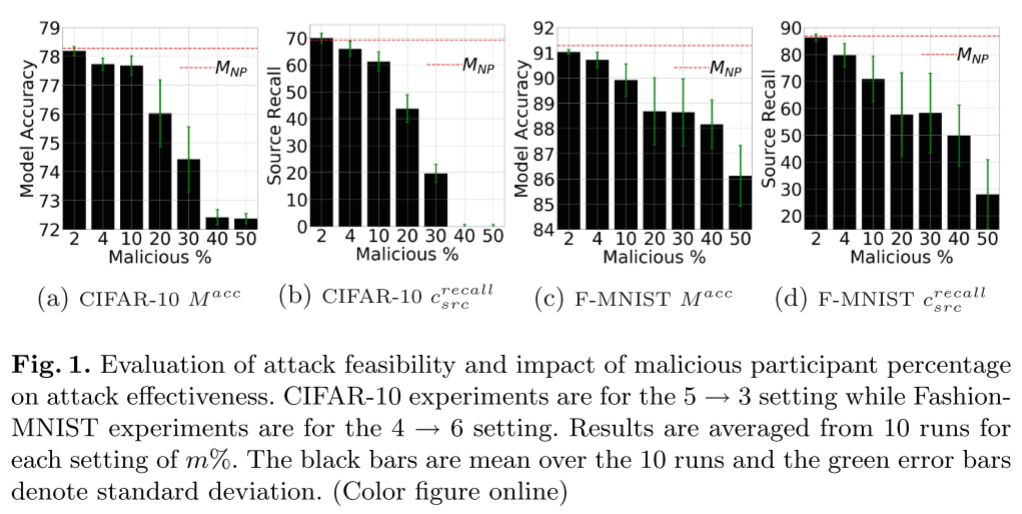
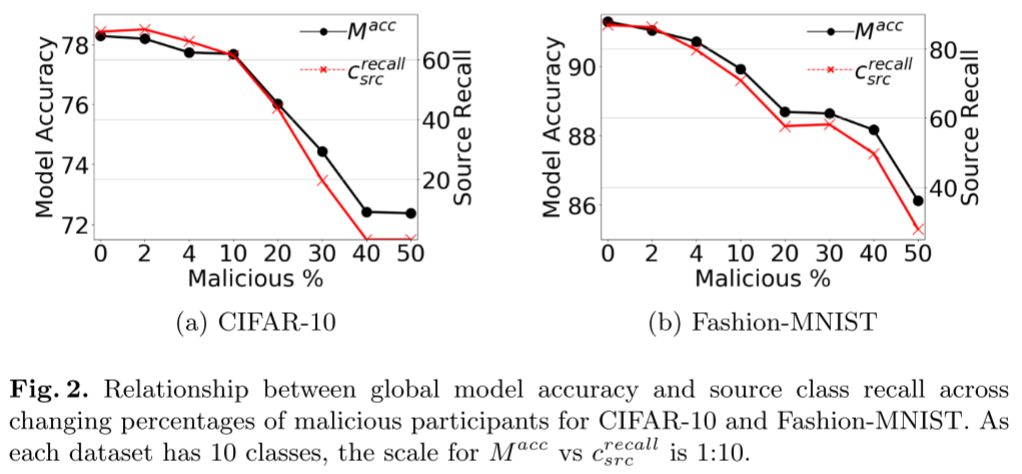
- 随着恶意参与者百分比的增加,全局模型效用(测试准确性)降低。
- 即使控制了总参与者人口的一小部分的对手也能够显着影响全球模型效用。
- 虽然两个数据集都容易受到标签翻转攻击,但数据集之间的脆弱性程度不同。
基于源类和目标类设置的脆弱性变化不太清楚。
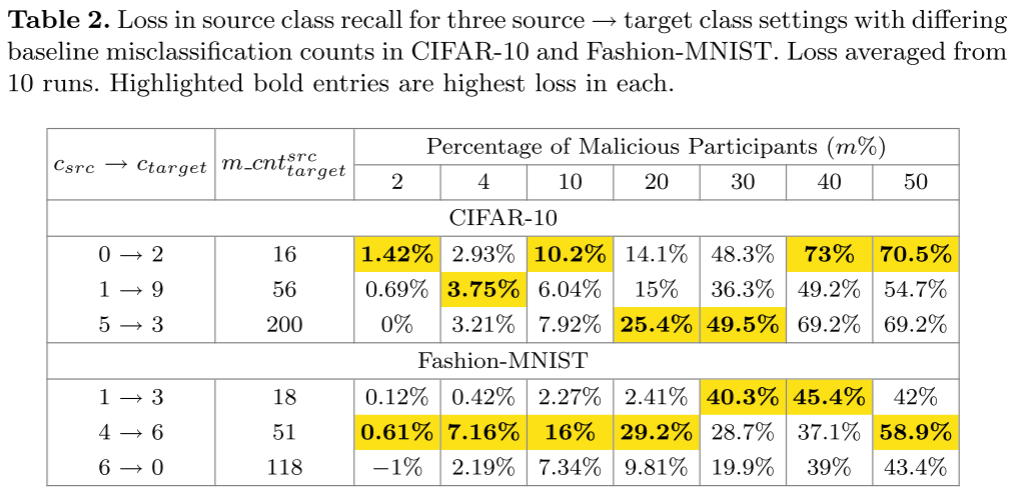
- 识别最易受攻击的源类和目标类组合对于敌手来说可能是一项不平凡的任务,并且非中毒误分类性能和攻击有效性之间不一定存在相关性。
标签翻转攻击似乎是有目标的。
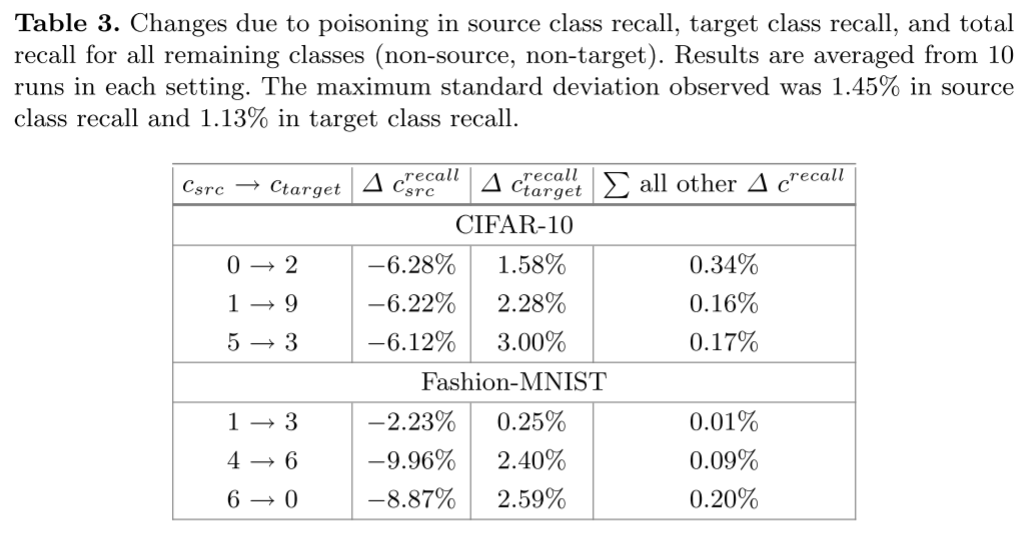
- 攻击导致源类召回(在大多数情况下下降 >6%)和目标类召回的实质性变化。然而,攻击对剩余类的召回率的影响要小一个数量级。
- 源类召回的变化占了 FL 系统中标签翻转攻击导致的全局模型精度下降的绝大部分。
标签翻转攻击中的攻击时机
一种情况是敌手仅在第 75 轮训练之前使恶意参与者可用,另一种情况是恶意参与者仅在第 75 轮训练之后可用。
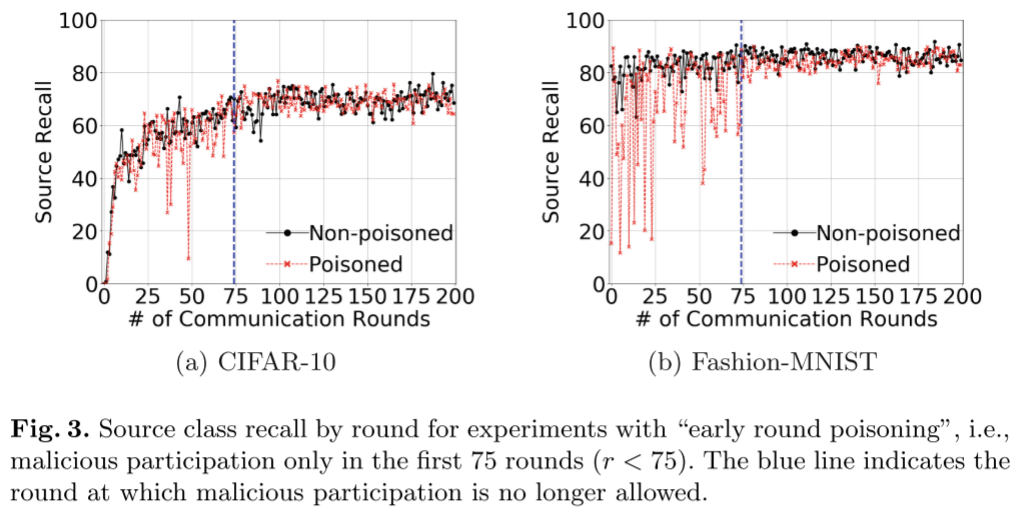
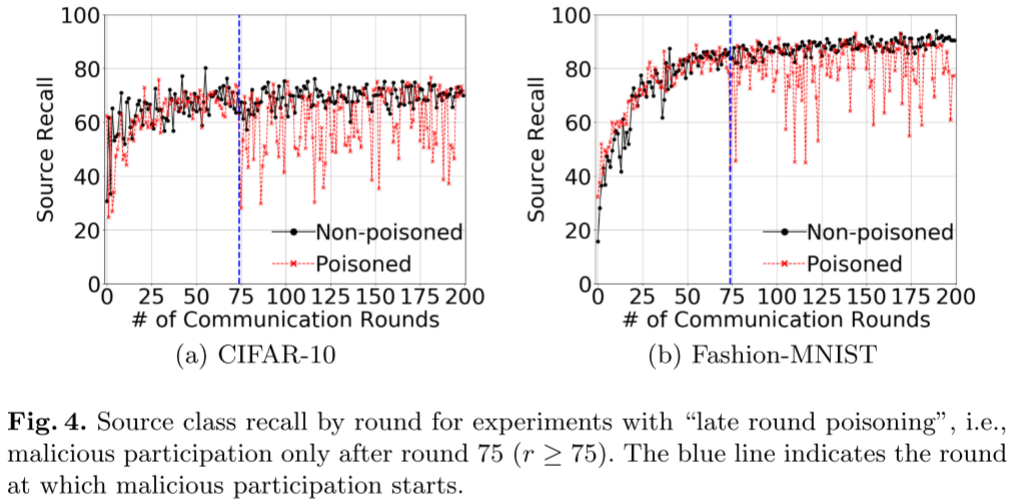
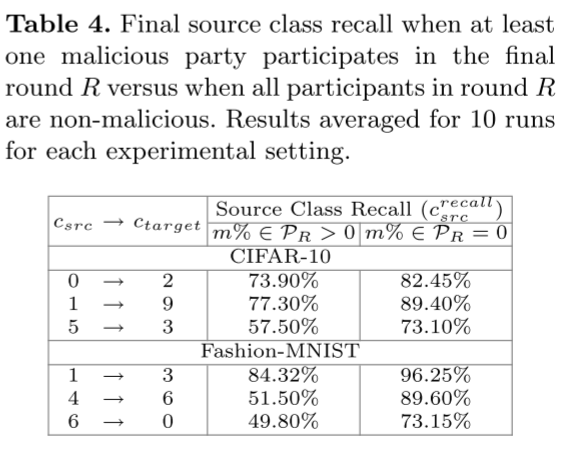
- 标签翻转攻击的效用影响主要与最后几轮训练中选择的恶意参与者的数量有关。
恶意参与者可用性
考虑到后期训练轮次中恶意参与对攻击有效性的影响,我们现在引入恶意参与者可用性参数 $\alpha$。通过改变$\alpha$,我们可以模拟对手在训练中的各个点控制受损参与者的可用性(即确保连接或电源接入)的能力。具体来说,$\alpha$ 表示恶意参与者的可用性,因此相对于诚实参与者,$\alpha$ 表示恶意参与者被选择的可能性。
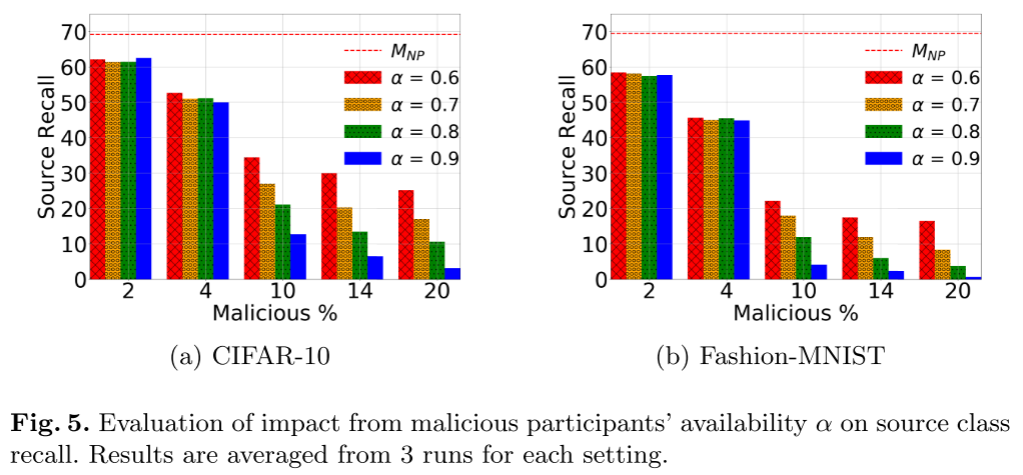
- 当对手在参与者池中保持有效的表示时(即 ≥10%),操纵恶意参与者的可用性可以对全局模型效用产生更大的影响,源类召回损失超过 20%。
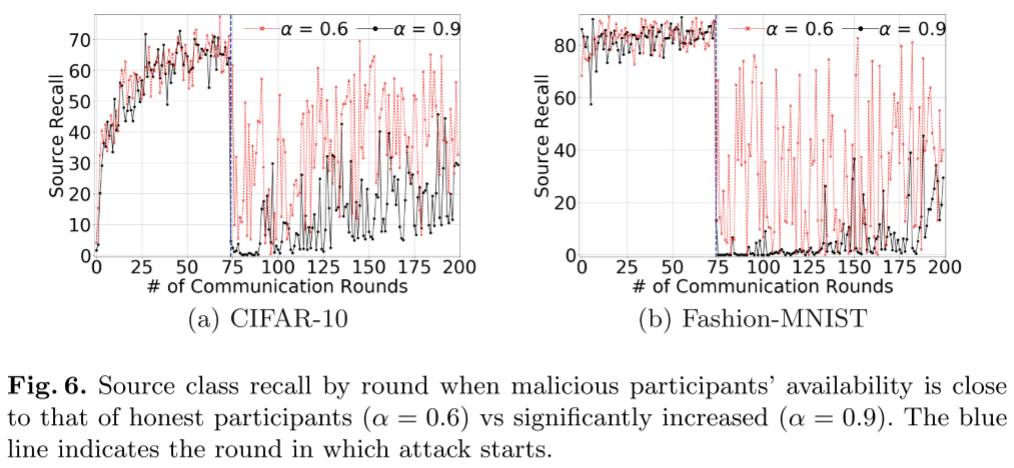
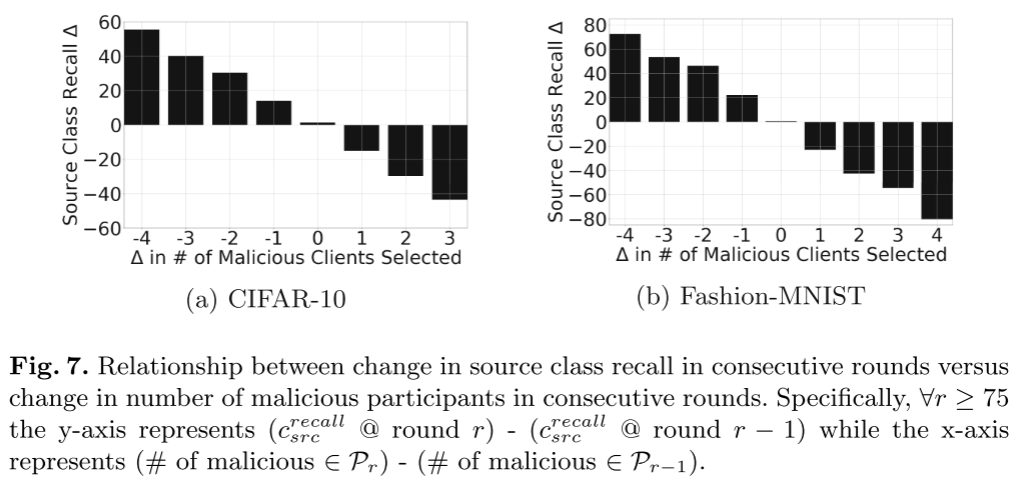
- 如果恶意参与者可以实现足够大的减少,DNN 即使在几轮 FL 训练中也可以显著恢复的可能性。
防御标签翻转攻击
主要思想:与诚实参与者对参数空间子集的更新相比,恶意参与者发送的参数更新具有独特的特征。然而,由于 DNN 有许多参数(即 $\theta_{r,i}$ 是极高维),因此手动分析参数更新是不平凡的。因此,我们提出了一种自动策略,用于识别相关参数子集,并使用降维(PCA)研究参与者更新。

- 服务器获取
$n$个用户的模型${\theta_i}$; - 对局部模型进行聚合得到全局模型
$\theta$; - 计算
$n$个用户的局部模型相对于全局模型的增量$\theta_{\Delta,i}=\theta_i-\theta$(相当于对更新进行了零中心化预处理)。定义类别$c_{src}$是怀疑被攻击者在标签翻转攻击中进行投毒的源标签,又由于某一类的概率仅由 DNN 结构最后一层的特定节点算得到,故仅提取$\theta_{\Delta,i}$中与$n_{c_{src}}$节点有关的子集$\theta_{\Delta,i}^{src}$,并将其放入列表$U$中; - 在经过对列表
$U$的多轮构建之后,对其进行标准化,然后对标准化之后的列表进行 PCA 降维,并得到可视化结果; - 然后对结果进行聚类,将最大的类视为良性更新,而恶意参与者的更新属于其他明显不同的聚类;
- 识别出恶意参与者后,聚合器可以将其列入黑名单,或在未来几轮中忽略其更新;
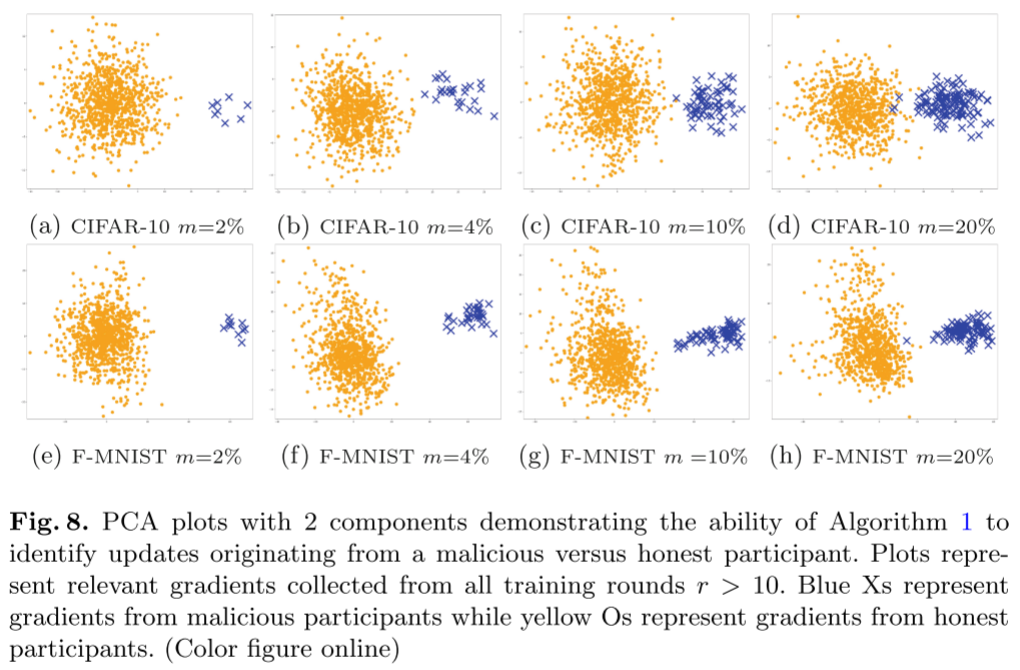
- 恶意参与者的更新属于明显不同的集群,而诚实参与者的更新则属于他们自己的集群
- 我们的防御不会受到“梯度漂移”问题的影响
总结
本文研究了针对 FL 系统的数据中毒攻击。我们证明了 FL 系统容易受到标签翻转中毒攻击,并且这些攻击会对全局模型产生显著的负面影响。我们还表明,对全局模型的负面影响随着恶意参与者比例的增加而增加,并且有可能实现有针对性的中毒影响。此外,我们还证明了对手可以通过增加后续回合中恶意参与者的可用性来增强攻击效果。最后,我们提出了一种防御措施,帮助 FL 聚合器将恶意参与者与诚实参与者分离。我们证明了我们的防御能够识别恶意参与者,并且对梯度漂移具有鲁棒性。