| 论文英文名字 | Analyzing Federated Learning through an Adversarial Lens |
|---|---|
| 论文中文名字 | 通过对抗性视角分析联邦学习 |
| 作者 | Arjun Nitin Bhagoji, Supriyo Chakraborty, Prateek Mittal, Seraphin B. Calo |
| 来源 | 36th ICML 2019: Long Beach, California, USA |
| 年份 | 2019 年 6 月 |
| 作者动机 | 研究在联邦学习中由单个非共谋恶意代理发起的模型中毒攻击的威胁 |
| 阅读动机 | 经典阅读 |
| 创新点 | 提出交替最小化策略进行模型中毒攻击 |
内容总结
主要贡献
- 目标模型中毒攻击
- 隐身模型中毒攻击
- 攻击拜占庭弹性聚合
- 与数据中毒和可解释性的联系
威胁模型
- 攻击模型
- 他们恰好控制一个非共谋的恶意代理,其索引为
$m$(限制恶意更新在全局模型上的影响); - 数据以 i.i.d 方式在代理之间分布(使得更容易区分良性和可能的恶意更新,并且更难实现攻击隐匿);
- 恶意代理可以访问训练数据
$D_m$的子集以及从与其对抗目标的一部分的训练和测试数据相同的分布中提取的辅助数据$D_{aux}$(???)
- 他们恰好控制一个非共谋的恶意代理,其索引为
- 对手目标
- 确保在服务器上学习的分类器对辅助数据进行有针对性的错误分类
$x_i$表示样本$y_i$表示真实标签$\tau_i$表示错误标签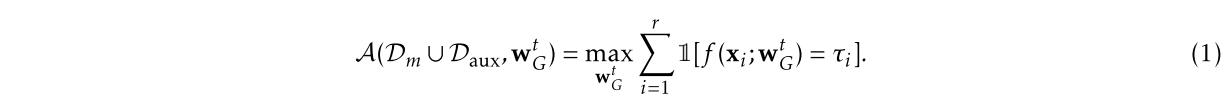
- 隐形指标
给定来自代理的更新,服务器可以检查两个关键属性。首先,服务器可以单独验证更新是否会改善或恶化全局模型在验证集上的性能。其次,服务器可以检查该更新在统计上是否与其他更新有很大不同。我们注意到,这些属性都没有作为标准联邦学习的一部分进行检查,但我们使用这些属性来提高成功攻击的门槛。
- 正确性检查:如果生成的模型的验证精度远低于通过聚合所有其他更新获得的模型的验证精度,服务器可以将更新标记为异常。阈值确定服务器可以容忍的性能变化程度。
$w_i^t=w_G^{t-1}+\delta_i^t$$w_{G \backslash i}^t=w_G^{t-1}+\sum_i\delta_i^t$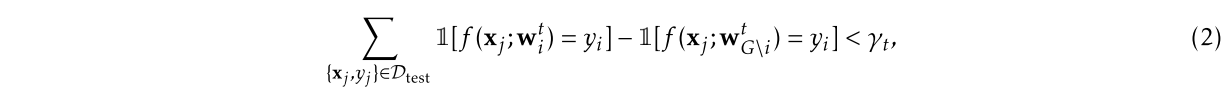
- 权重检查:特定更新和其他更新之间的成对距离范围指示了该更新与其他更新之间的差异。为了使恶意代理不被标记为异常,我们需要(一个公式)。此条件确保恶意代理和任何其他代理的距离范围与任何其他两个代理的距离范围没有太大差异。
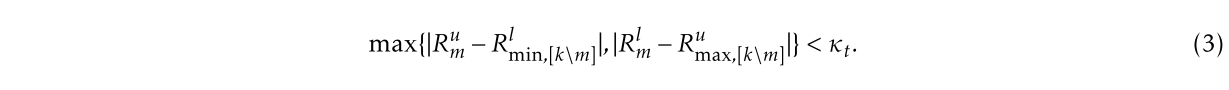
- 实验设置
- 数据集:Fashion-MNIST 和 UCI Adult Census dataset
- 模型:带有 dropout 的三层卷积神经网络和全连接神经网络
模型中毒攻击策略
挑战
从等式 1 可以看出,对手面临的两个挑战是显而易见的。
- 目标代表了一个困难的组合优化问题。
- 解决办法:根据交叉熵损失放宽了等式 1,以便可以使用自动微分。
- 对手无法访问当前迭代的全局参数向量
$w_G^t$,只能通过其提供给服务器 S 的权重更新$\delta_m^t$来影响它。 - 解决办法:使用基于对手可用的所有信息对
$w_G^t$值的估计$\hat{w}_G^t$进行优化
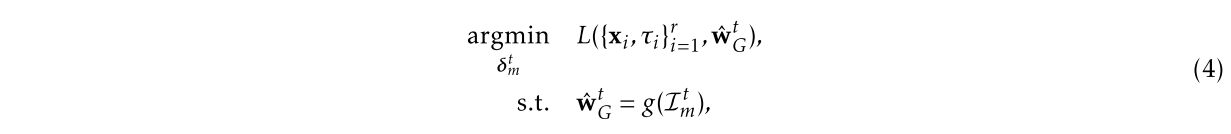
其中 $\hat{w}_G^t=w_G^{t-1}+\alpha_m\delta_m^t$
显式提升
思想
使用恶意客户更新的权重显式提升,旨在消除良性代理的综合影响。
步骤
恶意训练方将最终的梯度更新发送回服务器之前,需要对当前得到的梯度更新进行提升。最终将增强后的梯度更新发回服务器。
$\lambda=\frac{1}{\alpha_m}$
本轮更新之后的全局模型的估计值等于恶意训练方的本地模型。此时恶意训练方的本地模型已经替换了全局模型。
结果
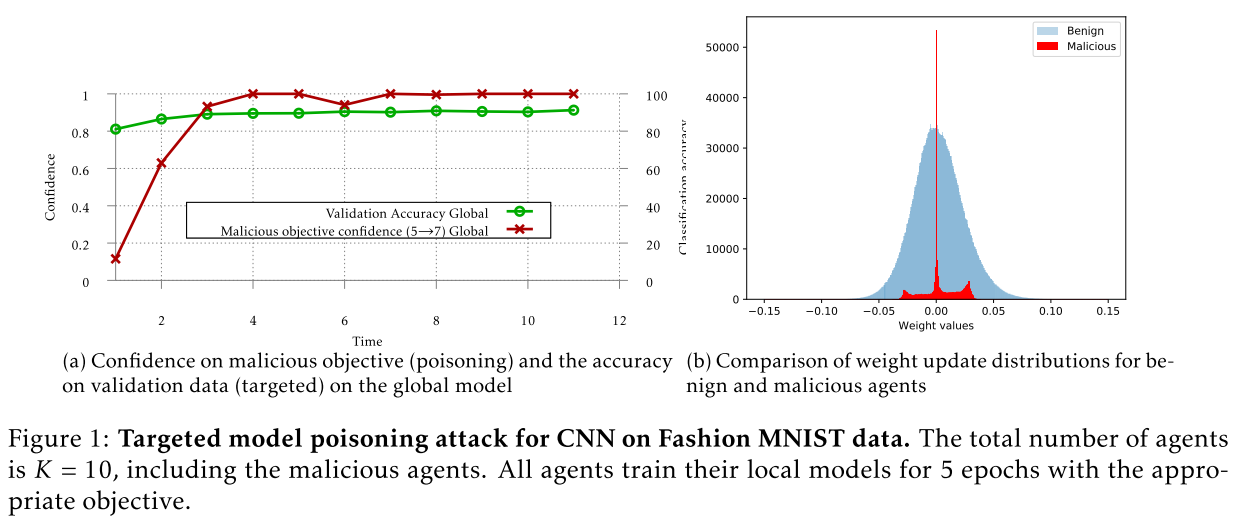
与来自良性代理的权重更新相比,来自恶意代理的更新更稀疏,范围更小
不足
使用显式提升方法的攻击理论上能够实现攻击的目的。但同时还有一个巨大的缺点,很容易被服务器检测出来从而最终没有办法完成攻击任务。使用精确度检测、权值分布检测可以将使用了显式提升方法的恶意训练方检测出来。
隐形攻击
思想
攻击方根据服务器的两种检测方法,在原有的实现攻击目标(等式 4)的基础上,添加了两个用于实现隐身目标的损失函数。
步骤
第一,由于训练数据是 i.i.d 的,所以在添加了基于本地正常数据的训练损失函数之后,恶意训练方的本地模型会在正常的数据集上表现出来的性能更好,从而在精确度检测时,服务器更难把恶意训练方检测出来。 $L(D_m, w_m^t)$
第二,为了保证攻击方上传的梯度更新和正常训练方上传的梯度更新尽可能接近,攻击方在进行本地模型训练的过程中,将欧氏距离限制加入了目标函数,用来限制恶意的训练方与正常的训练方的梯度更新之间的距离。 $\rho{\lVert\delta_m^t-\bar{\delta}_{ben}^{t-1}\rVert}_2$
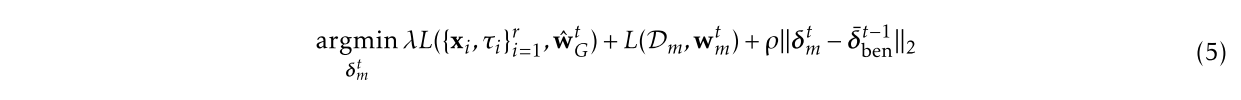
结果
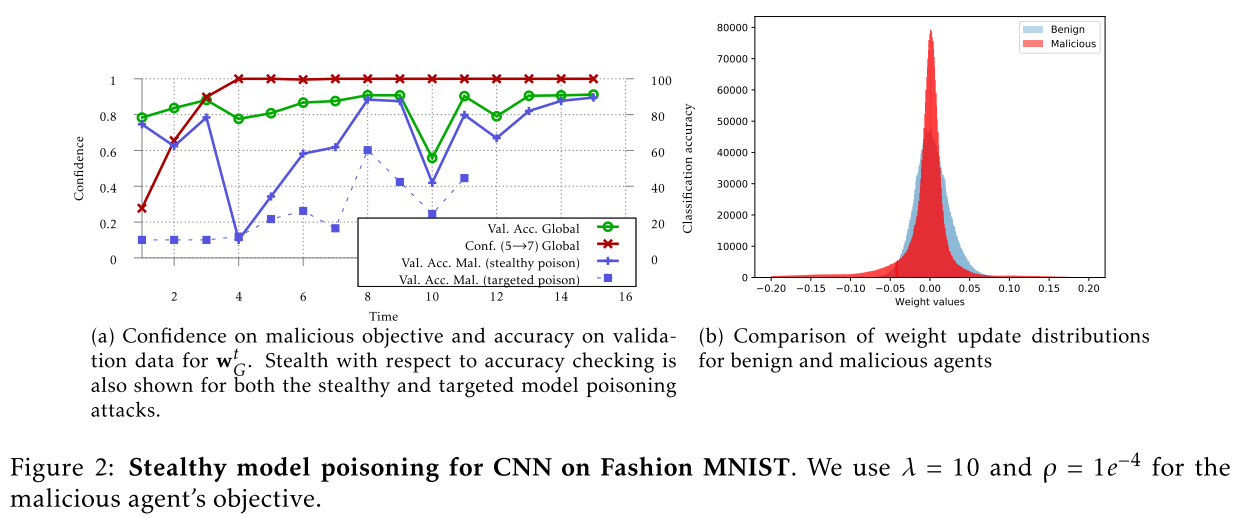
优点
不论服务器选择基于精确度检测的方法,还是基于权值分布检测的方法,使用隐形模型中毒方法的攻击方都比使用显示提升方法的攻击方更难检测。
缺点
虽然隐身模型中毒攻击可以确保在不被两种检测方法发现的同时,有针对性地使全局模型中毒,但它并不能确保在每次迭代中都起作用。
交替最小化
思想
提出了一个交替最小化公式,该公式考虑了模型中毒和隐身,并允许恶意权重更新在几乎所有回合中避免检测。
步骤
在每一个迭代周期中,训练在每一个 epoch 都做如下操作:
- 从当前的模型参数,最小化攻击目标,训练得到一个梯度更新;
- 利用显示提升的思想对梯度进行增强,与当前的模型参数相加得到中间步骤的模型参数;
- 从所得到的中间步骤的模型参数开始,最小化之前提到的两个隐形目标,最终得到一个新的模型,用于下一个 epoch。
结果
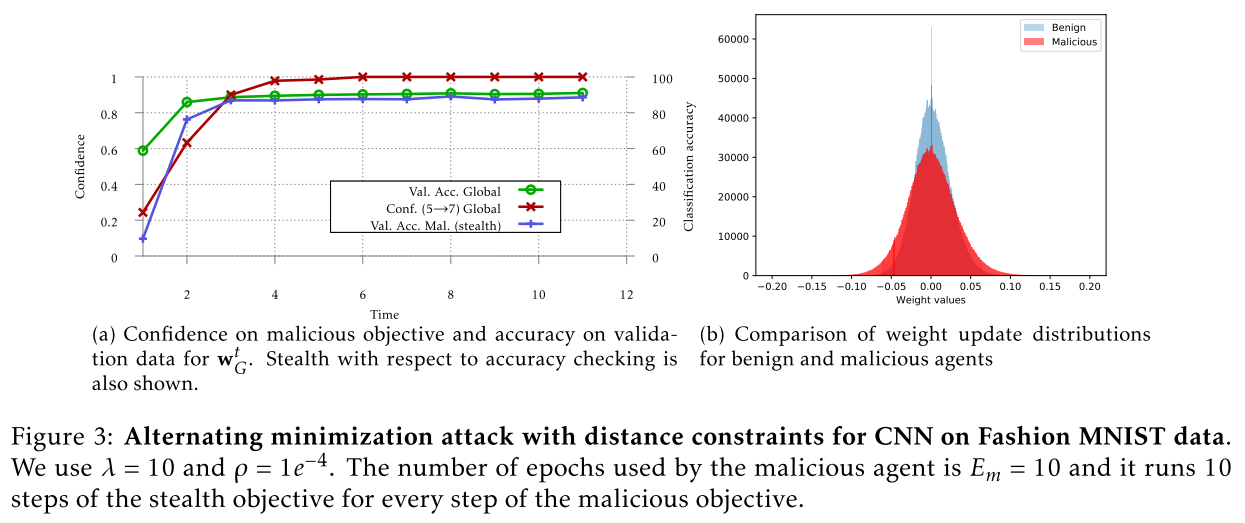
恶意模型的验证数据的准确性接近于全局模型的准确性
优点
攻击方通过交替最小化,将攻击目标和隐身目标分开进行独立的训练,使得这两个目标都具有足够低的损失值。可以对较难的那个目标进行更多数量的 steps 的优化。
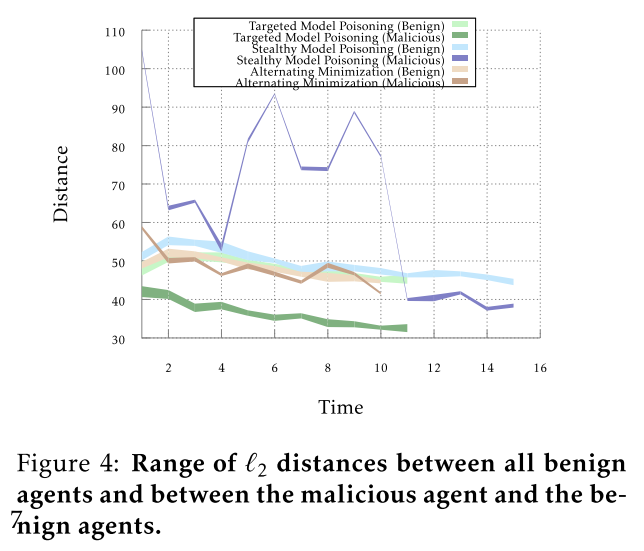
攻击拜占庭弹性聚合
拜占庭弹性聚合机制对我们的攻击缺乏鲁棒性。
Krum 和 Coordinate-wise median

讨论
- 模型中毒攻击比联邦学习环境中的数据中毒更有效(提升)
- 可解释性方法对模型中毒攻击的脆弱性

总结
本论文中的攻击算法对于攻击之后的全局模型的估计值是十分简单的,并没有考虑其余正常训练方的梯度更新的影响,所以还可以进一步提高攻击算法的性能。最后,论文通过实验证明:即使是高度受约束的单个攻击方也可以进行模型中毒攻击,同时保持隐身性。因此需要提高研究联邦学习鲁棒性以及制定有效防御策略的必要性。
参考
问题
- 什么是联邦学习中的共谋?