| 论文英文名字 | Poisoning Attack in Federated Learning using Generative Adversarial Nets |
|---|---|
| 论文中文名字 | 使用生成对抗网络的联邦学习中的中毒攻击 |
| 作者 | Jiale Zhang, Junjun Chen, Di Wu, Bing Chen, Shui Yu |
| 来源 | 18th IEEE International Conference On Trust, Security And Privacy In Computing And Communications |
| 年份 | 2019 年 8 月 |
| 作者动机 | 在不损害任何良性参与者的情况下成功发起中毒攻击 |
| 阅读动机 | |
| 创新点 | 使用生成对抗网络进行构造中毒攻击 |
内容总结
生成对抗网络
作用
在原始图像集的基础上生成高质量的假图像
原理
GAN 结构中有两个神经网络,即生成器(G)和鉴别器(D):
- 生成器(Generator):
$G$用于生成图片,其输入是一个随机的噪声$\boldsymbol{z}$(遵循高斯或均匀分布等先验分布),通过这个噪声生成图片,记作$G(\boldsymbol{z})$ - 判别器(Discriminator):
$D$用于判别图像是否来自生成器或真实图片,对应的,其输入是一整图片$\boldsymbol{x}$,输出$D(\boldsymbol{x})$表示的是图片$\boldsymbol{x}$为真实图片的概率
在 GAN 框架的训练过程中,希望生成器 $G$ 生成的图片尽量真实,能够欺骗过判别器 $D$;而希望判别网络 $D$ 能够把 $G$ 生成的图片与真实图片中区分开。这样的一个过程就构成了一个动态的“博弈”。最终,GAN 希望能够使得训练好的生成器 $G$ 生成的图片能够以假乱真,即对于判别网络 $D$ 来说,无法判断 $G$ 生成的图片是不是真实的。
目标函数
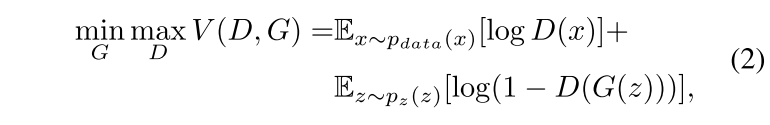
威胁模型
联邦学习场景
多个参与者(N >= 2),其中有一个或多个攻击者。
攻击者的目标
在训练阶段破坏全局模型,同时伪装成良性参与者
- 样本生成:攻击者可以成功地从良性参与者的训练数据中模仿原型样本,而无需直接访问他们的本地数据集。
- 中毒任务准确性:一旦在生成的假样本上训练的中毒局部更新被上传到中央服务器,全局模型应该在攻击后的几轮内对中毒任务执行高准确性。
- 主要任务精度:全局模型还应在主要任务(非中毒)上呈现高精度,以防止全局模型被丢弃。
攻击者的能力
- 主动:假设攻击者是一个主动的内部人员,因为他可以在本地部署 GAN 架构,修改任何训练输入,操纵训练过程,甚至改变本地更新的规模。
- 全知识:攻击者完全了解模型结构,因为联邦学习中的所有参与者事先就共同的学习目标达成了一致。
攻击构造
Delta
思想
攻击者首先充当一个善意的参与者,然后秘密地训练一个 GAN 来模仿其他参与者的训练集的原型样本,然后攻击者向 GAN 生成的数据添加错误的标签。之后,这些有毒的数据被注入到训练过程中,以获得局部模型更新,从而进一步破坏全局模型。更改训练配置,例如历元数和学习速率,以使中毒全局模型在主任务和中毒任务上都表现良好。
步骤
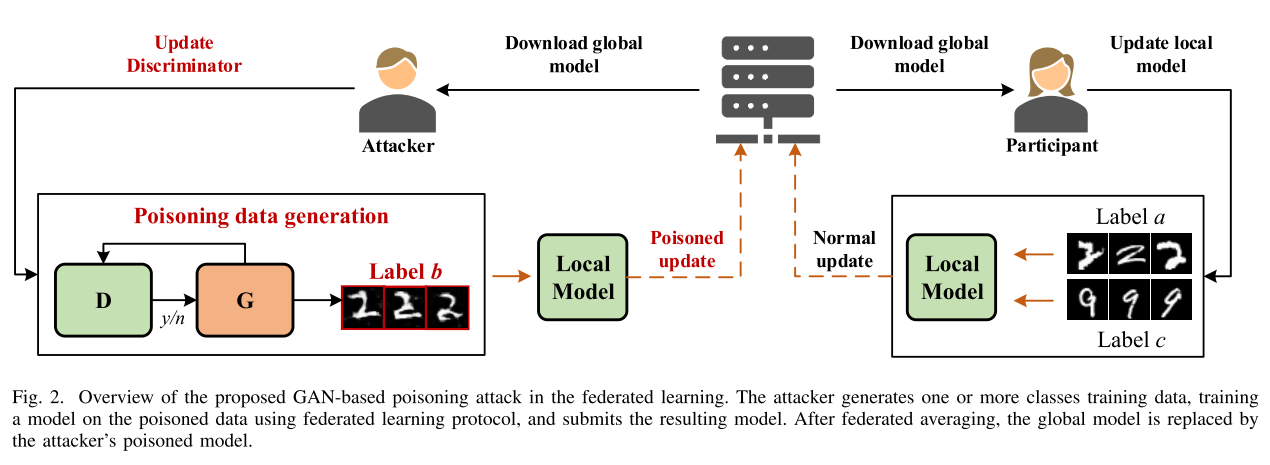
- 假设 P 和 A 是联邦学习系统中的两个参与者,他们拥有不同的私有训练数据集(a 类和 b 类);
- 运行联邦学习协议几轮,更新全局模型,直到精度达到一定水平;
- 对于参与者 P:(1)下载全局模型以替换其局部模型的参数;(2)在本地数据集上训练模型,并将本地更新
$\Delta L^i$上传到中央服务器; - 对于攻击者 A:(1)下载全局模型以替换其本地模型的参数;(2)创建新本地模型的副本作为 D(鉴别器),并在 D 上运行 G(生成器),以模拟来自参与者 P 的针对类别 b 的样本;(3)将生成的 a 类样本标记为 b 类,并将中毒数据样本插入 A 的本地数据集;(4) 基于合并的数据集训练其局部模型,并生成中毒的局部模型更新
$\Delta L^p$;(5)使用商议因子$\lambda$放大$\Delta L^p$,并将中毒更新$\lambda\Delta L^p$发送给中央服务器; - 重复步骤 3 和 4,直到全局模型收敛。

实验
- 数据集:MINST 和 AT&T
- 模型:基于卷积神经网络的架构来构建分类器和判别器,并基于反卷积网络构建相应的生成器
- 实验场景:单个攻击者和多个攻击者
实验结果

基于 GAN 的生成模型可以成功地模拟参与者的原始样本
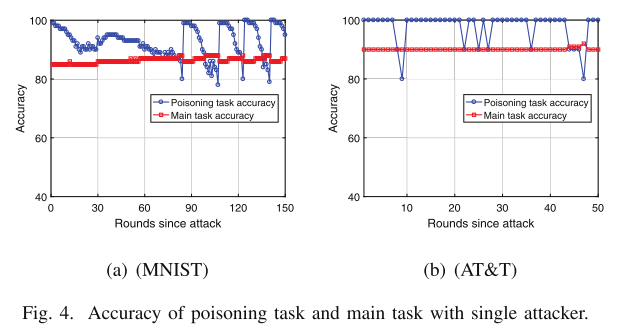
我们的投毒任务准确率平均可以保持在 90%
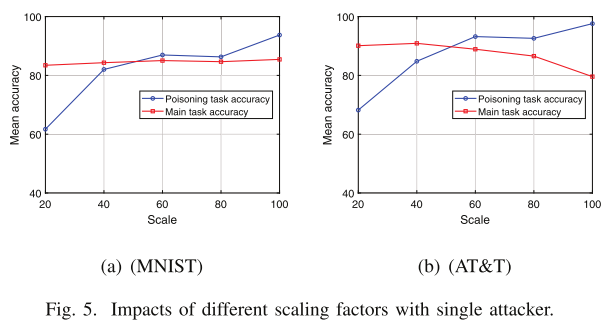
- 我们的中毒攻击在 MNIST 和 AT&T 数据集上都可以达到很高的准确率
- 即使使用小规模因子(例如 20),中毒任务的准确率也可以达到 60%
- 不同的缩放因子对主要任务的准确性没有大的影响
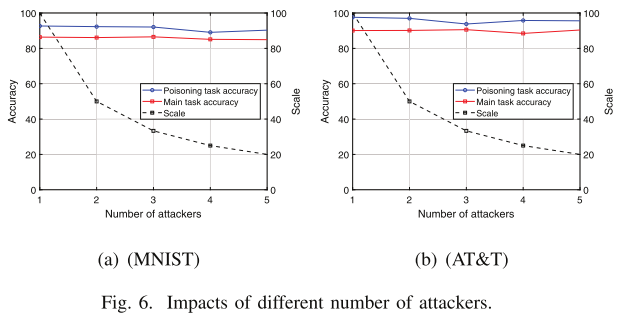
- 中毒任务的准确率保持稳定的趋势,成功率在90%以上,主要任务的准确率保持在 85% 左右,且不受攻击者数量增加的影响
- 可以通过增加所有参与者中的攻击者比例来规避未知检测机制
总结
在这项工作中,我们提出了一种针对联邦学习系统的新型中毒攻击。我们表明,任何内部参与者都可以发起中毒攻击,他们部署生成对抗网络 (GAN) 框架来模仿其他参与者的训练样本。 在现实威胁假设下,我们的攻击比现有的数据中毒攻击更加通用和有效。 原因是我们构建的攻击者只需要作为一个良性的内部人员参与联邦学习系统并生成其他参与者的私人训练数据,而之前的数据中毒攻击需要强大的攻击者侵入其他参与者的训练过程。通过对两个基准数据集的评估,我们发现我们的中毒攻击可以由内部参与者使用 GAN 成功发起,并且全局模型在中毒任务和主要任务上都具有很高的准确性。