| 论文英文名字 | Learning to Detect Malicious Clients for Robust Federated Learning |
|---|---|
| 论文中文名字 | 学习检测恶意客户端以实现稳健的联邦学习 |
| 作者 | Suyi Li, Yong Cheng, Wei Wang, Yang Liu, Tianjian Chen |
| 来源 | CoRR, February 2020 |
| 年份 | 2020 年 2 月 |
| 作者动机 | (1)现有的拜占庭容忍算法无法在联邦学习设置中实现令人满意的模型性能。(2)对抗性攻击的防御机制主要是为蓄意的目标攻击而设计的,在非目标的拜占庭攻击下无法生存。 |
| 阅读动机 | |
| 创新点 | 根据光谱(低维嵌入)检测异常模型更新 |
内容总结
光谱异常检测的好处
- 适用于无监督和半监督设置,这使得它对恶意模型更新未知且无法事先准确预测的联邦学习场景特别有吸引力。
- 使用具有动态阈值的变分自动编码器(VAE),由于检测阈值只有在收到所有客户端的模型更新后才确定,因此攻击者无法先验地学习检测机制。
- 通过检测和清除中心服务器中的恶意更新,可以完全消除它们的负面影响。
问题定义
我们考虑一个典型的 FL 设置,其中多个客户端使用 FedAvg 算法 [McMahan et al., 2017] 协作训练在中央服务器中维护的 ML 模型。我们假设攻击者只能检查模型的陈旧版本(即陈旧的白盒模型检查 [Kairouz et al., 2019]),这在 FL 中通常是这种情况。我们还假设可用于训练光谱异常检测模型的公共数据集的可用性。这一假设在实践中普遍成立 [Li and Wang, 2019]。事实上,拥有公共数据集对于 FL 中的神经网络架构设计是必不可少的。
对抗性更新如何损害模型性能?
考虑一个简单的线性模型,以下定理量化了恶意更新的负面影响。
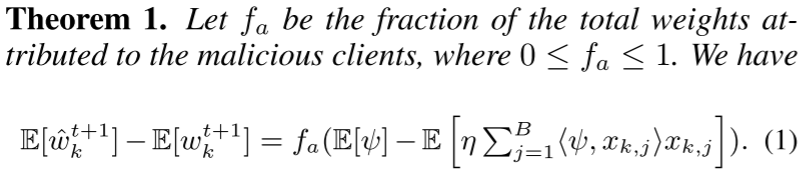
定理 1 指出恶意更新的影响由两个因素决定:(i) 攻击者添加的噪声 $\psi$,(ii) 在 FL 系统中归因于恶意客户端的总权重的比例 $f_a$。
定理 1 还表明:添加少量噪声 $\psi$ 不会导致模型权重出现较大偏差。
光谱异常检测
- 检测恶意更新
基本思想:在去除数据实例中的噪声和冗余特征后,可以在低维潜在空间中轻松区分正常数据实例和异常数据实例的嵌入。
一种有效的近似低维嵌入的方法是使用编码器-解码器体系结构训练模型。编码器模块将原始数据实例作为输入并输出低维嵌入。解码器模块然后接受嵌入,在此基础上重建原始数据实例并生成重建错误。然后利用重构误差优化编码器-解码器模型的参数,直到其收敛。因此,经过对正常实例的训练后,该模型可以识别异常实例,因为它们触发的重建误差比正常实例高得多。

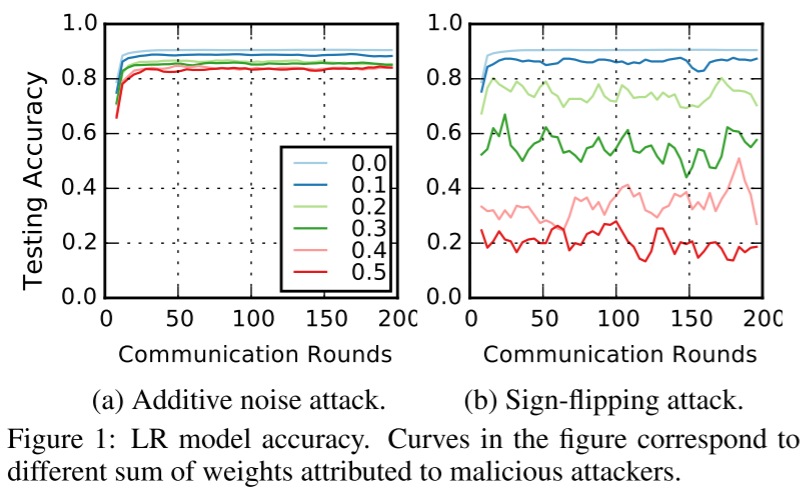
左图中恶意客户端的攻击是对 MNIST 数据集的加噪声攻击。右图中恶意客户端的攻击是对 FEMINST 数据集的符号翻转攻击。
- 删除恶意更新
在获得光谱异常检测模型后,我们将其应用于每一轮 FL 模型训练,以检测恶意客户端更新。 通过编码和解码,每个客户端的更新都会产生一个重构错误。 请注意,恶意更新会导致比良性更新更大的重建错误。 这种重构错误是检测恶意更新的关键。
在每一轮通信中,我们将检测阈值设置为所有重建错误的平均值,从而产生一种动态阈值策略。重建错误高于阈值的更新被视为恶意更新,并从聚合步骤中排除。聚合过程只考虑良性更新,每个良性更新的权重根据其本地训练数据集的大小进行分配。
实验
- 数据集:MINST,FEMINST 和 Sentiment140
- ML模型:LR模型,CNN 和 RNN
- 评估指标:测试准确率
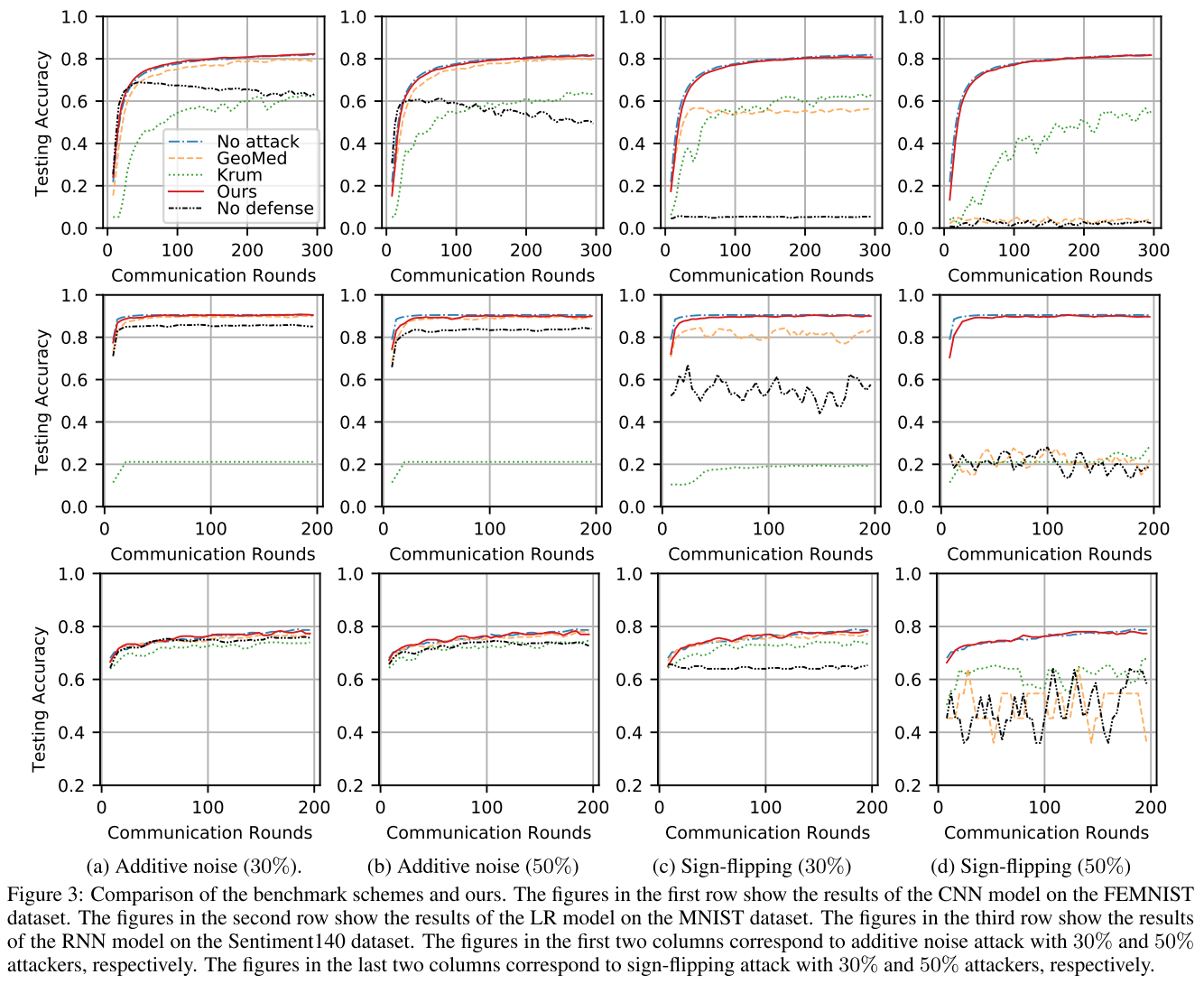
我们提出的基于检测的方法在所有设置中都达到了最佳性能。
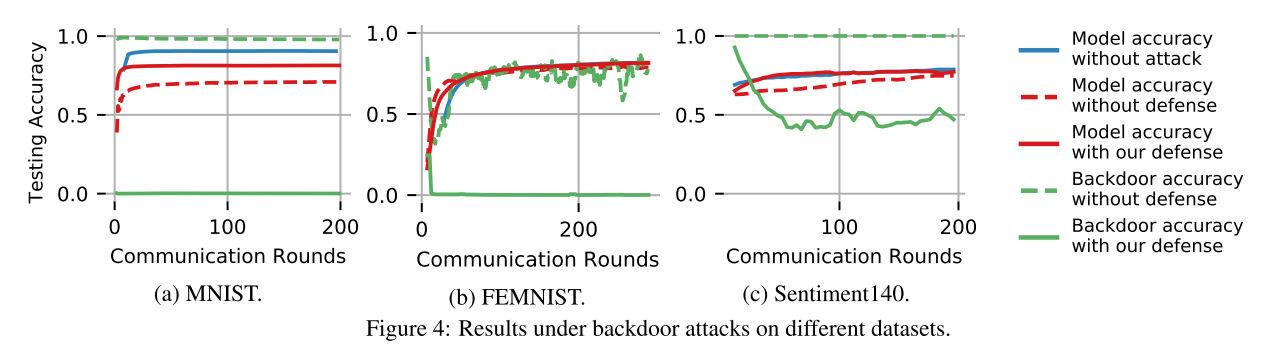
我们的解决方案可以减轻后门攻击对所考虑的数据集的影响。