| 论文英文名字 | FLARE: Defending Federated Learning against Model Poisoning Attacks via Latent Space Representations |
|---|---|
| 论文中文名字 | FLARE: 通过潜在空间表示保护联邦学习免受模型中毒攻击 |
| 作者 | Ning Wang, Yang Xiao, Yimin Chen, Yang Hu, Wenjing Lou, Y. Thomas Hou |
| 来源 | 17th AsiaCCS 2022: Nagasaki, Japan |
| 年份 | 2022 年 5 月 |
| 作者动机 | 专注于分析模型参数的现有防御措施在检测这种精心设计的有毒模型方面效果有限 |
| 阅读动机 | |
| 创新点 | 利用模型的倒数第二层表示 (PLRs) 来表征对每个局部模型更新的对抗性影响 |
内容总结
预备知识
- MPAs 分类
- 非目标攻击:使模型收敛到次优最小值或使模型完全发散。
- 目标攻击(后门攻击):对手希望模型只对一组选定的样本进行错误分类,对其在主要任务上的性能影响最小。(根据物理注入触发器的需要可以分类)
- 语义后门攻击:不涉及向输入中物理注入触发器,触发器是包含在原始图像中的语义特征。
- 木马后门攻击:攻击者需要通过修改所有或部分训练数据,将后门/触发器物理注入到 ML 模型中。
- MPAs 防御对策
- 拜占庭弹性聚合规则(BRARs):在全局模型聚合过程中通过统计方法选择数据,如 KRUM 。
- 使用异常检测方法来检测恶意的本地模型更新并将它们排除在聚合之外。
系统模型
- 具有信任分数的联邦学习
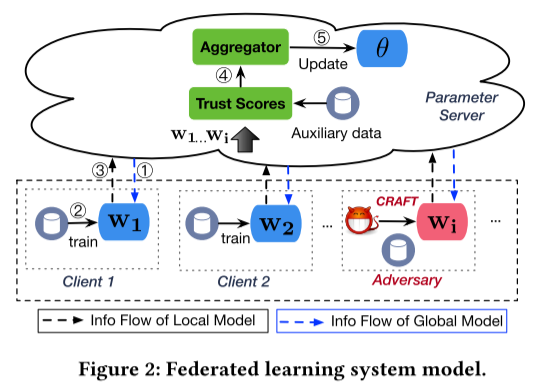
在系统启动时,PS 初始化 $\theta$ 。然后每次训练迭代的工作如下:
- PS 首先选择多个客户端并将
$\theta$分发给他们; - 每个选定的客户端,比如
$C_i$,初始化$w_i = \theta$并使用其本地数据训练模型; - 本地训练结束后,
$C_i$将其模型更新$\delta_i$提供给 PS; - PS 使用客户端提供的本地模型更新来计算每个客户端
$C_i$的信任分数$S_i$; - 最后,PS 聚合由信任分数加权的局部模型更新,并通过以下方式更新全局模型:
$\theta = \theta + \sum_iS_i\delta_i$。
在 FL 任务结束时,PS 输出最终的全局模型。
- 威胁模型
- 假设恶意客户端的数量少于
$0.5n$ - 每个恶意客户端都是白盒对手:攻击者可以访问全局模型参数和其他客户端的模型更新。
- 假设恶意客户端的数量少于
倒数第二层表示
- 动机
- 什么是倒数第二层?
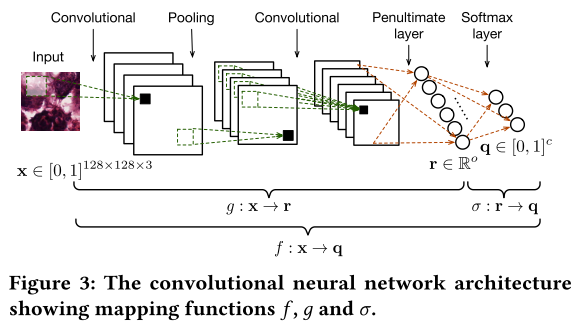
函数 $g$ 的输出是一个 PLR,用 $r \in \mathbb{R}^o$ 表示。
- 它在分离 MPA 中的作用

意味着 r 与模板 $\omega_k$ 之间的距离越小(当 r 与其他模型之间的距离固定时),r 被分类为类 k 的可能性就越大。

意味着 PLR 空间的差异将转化为相应输出概率的差异。
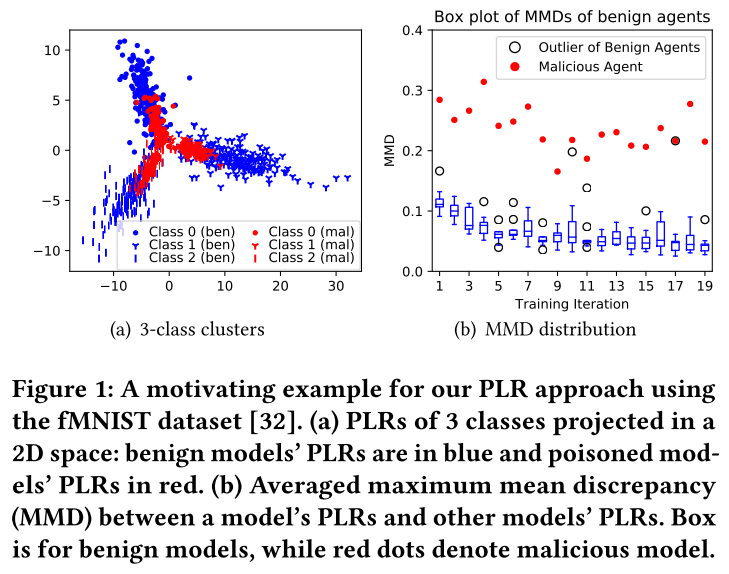
- 可视化 PLR 分布
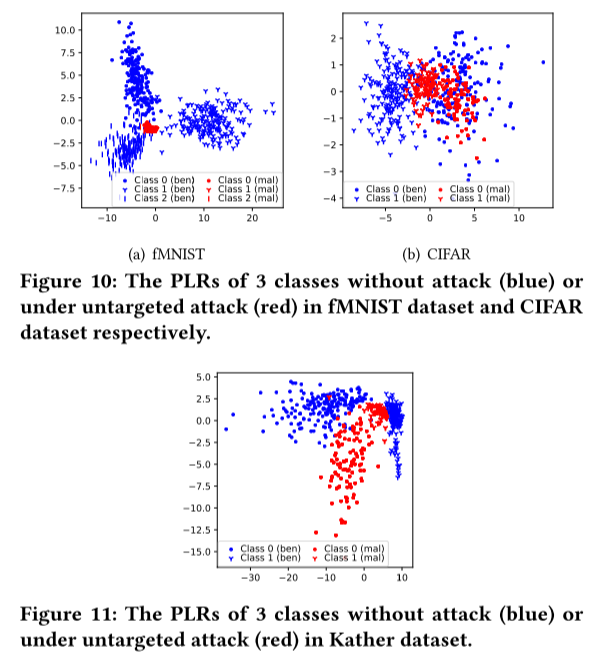
我们观察到良性模型的 PLR 遵循一个分布,而恶意模型的 PLR 则偏离它。
分布偏差的关键原因是良性模型之间的 PLR 距离小于良性模型和恶意模型之间的 PLR 距离。
FLARE: 防御 MPAs
- FLARE 概述
FLARE (Federated learning + LAtent-space REpresentations)
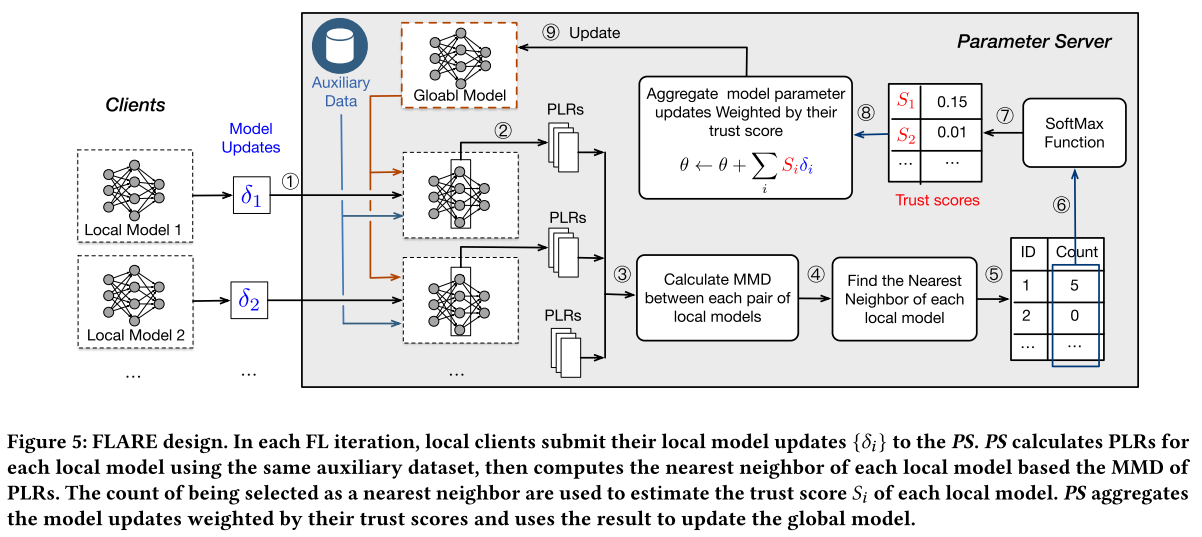
- 本地客户端首先将其本地模型更新
$\delta_i$提交给 PS; - PS 使用辅助数据集计算每个本地模型的 PLR ;
- FLARE 根据 PLR 的最大平均差异 (MMD) 计算每个局部模型的最近邻。一个客户端被选为其他客户端最近邻居的计数用于估计其信任分数
$S_i$; - 最后,PS 聚合由信任分数加权的模型更新,并使用它来更新全局模型。

- 详细设计
与传统的 FL 系统相比,FLARE 在 PS 上有两个不同之处:
(1)在一开始,PS 通过使用辅助数据集 D 训练而不是执行随机初始化来初始化全局模型。这个过程可以加速训练过程。它还可以帮助客户对 D 做出正确的预测,从而增加良性模型的 PLR 遵循一个分布的概率。
(2)在每次学习迭代的聚合阶段,PS 估计每个模型更新的信任分数,并通过他们的信任分数聚合它们。
如何估计信任分数?
$g_{w_j}: x \in \mathbb{R}^{d1 \times d2 \times d3} \rightarrow r \in \mathbb{R}^o$
$R_j := \{g_{w_j}(x_1),...,g_{w_j}(x_m)\}$
FLARE 对 $R_i$ 和 $R_j$ 应用 MMD(最大平均差异)来测试两个 PLR 序列是否遵循相同的分布。
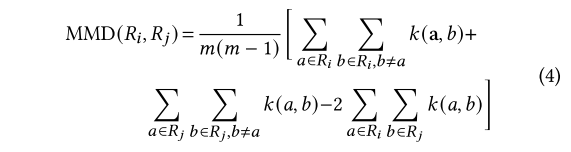
FLARE 利用最近邻的计数来估计模型更新的信任分数。PS 根据 MMD 分数为每个局部模型选择前 50% 的最近邻。一旦 $w_i$ 被任何 $w_j$ 选择(𝑗 ≠ 𝑖),$w_i$ 的计数 ${ct}_i$ 就会增加一。计数 ${ct}_i$ 值表示可信度。然后我们使用带温度的 softmax 函数将计数值转换为信任分数:
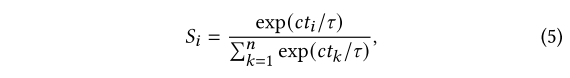
实验
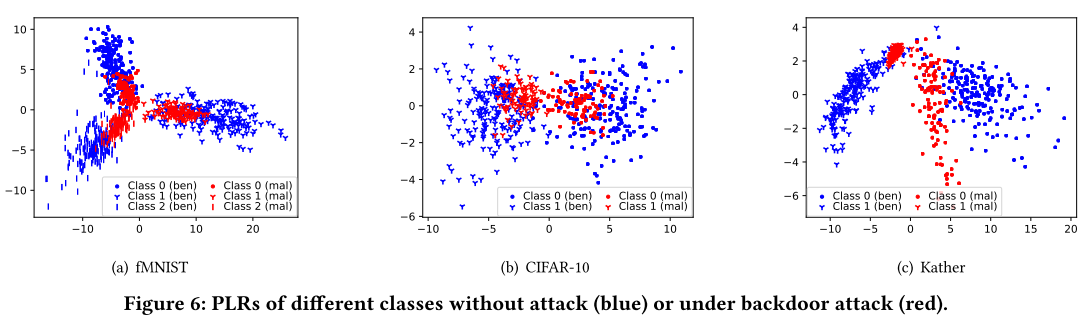
- 数据集:fMNIST 数据集、CIFAR-10 数据集和 Kather 数据集
- 模型:VGGNet
- MPAs:Attack-Krum-Untargeted, Attack-TM-Untargeted ,Attack-Krum-Backdoor , and Attack-Coomed-Backdoor
- 防御(baselines):Krum, Coomed, TrimmedMean, Bulyan, and FLTrust
-
评估指标:目标标签的模型置信度、攻击成功率(ASR)和干净数据的模型准确度(Acc)
-
实验结果
- 后门攻击
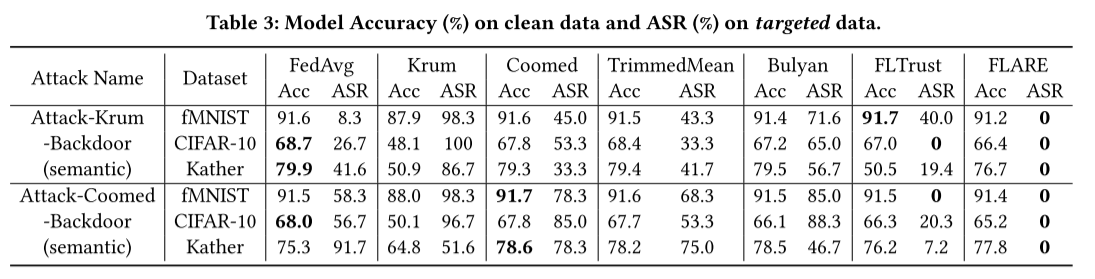
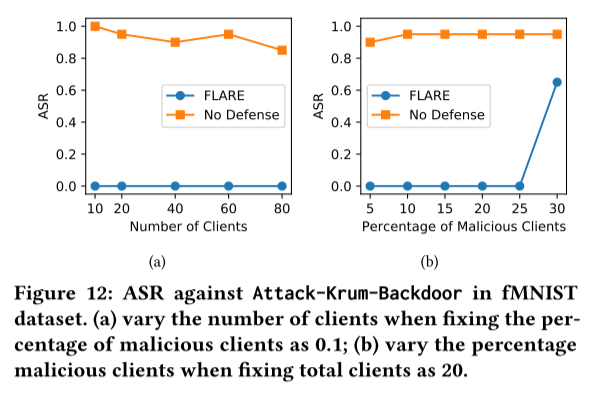
一个 MPA 不仅可以成功攻击其目标 BRAR,还可以破坏其他 BRAR。相反,我们提出的 FLARE 可以在各种数据集中将 ASR 降低到接近零的小值。
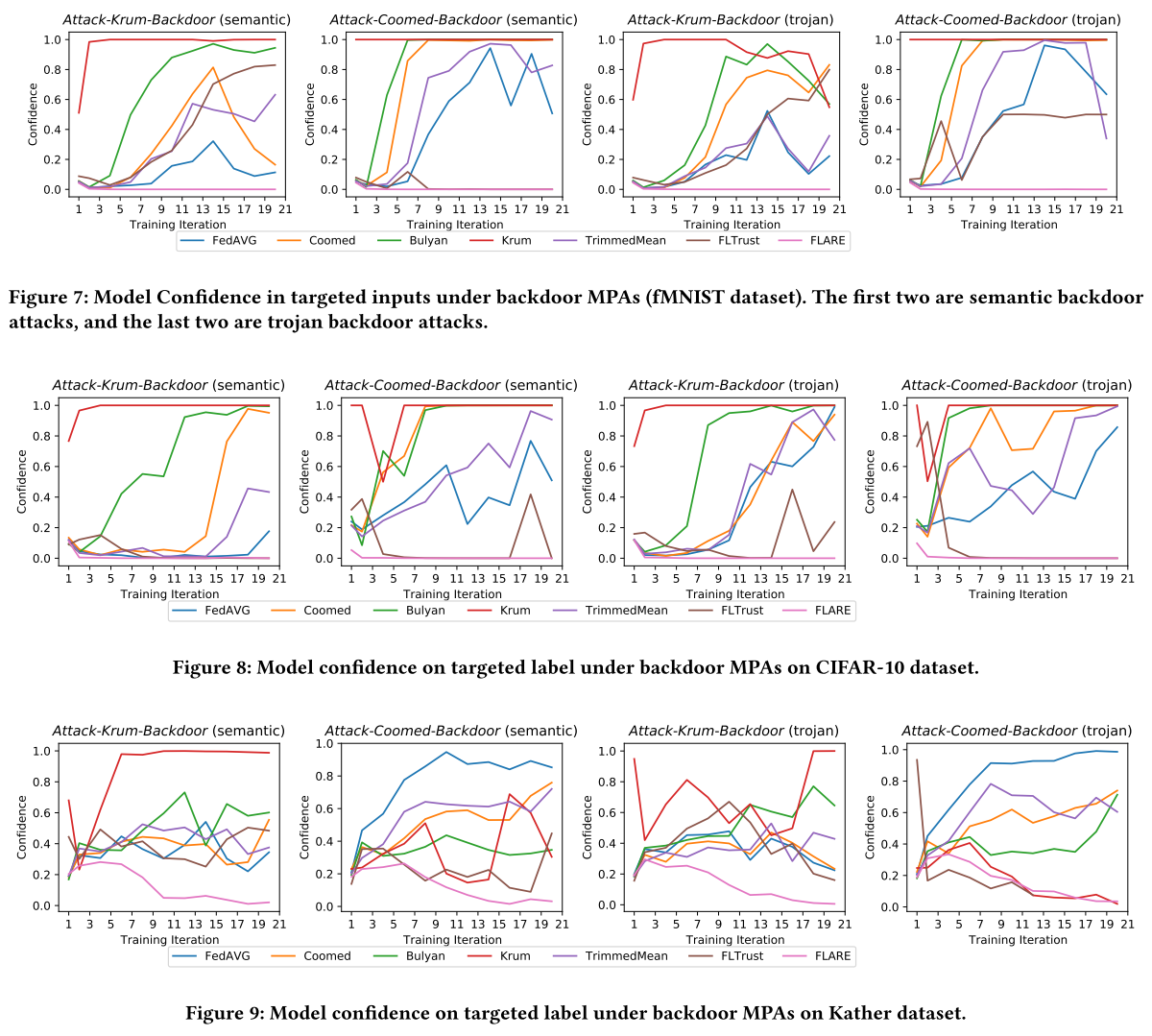
FLARE 成功地防御了四种后门攻击
- 非目标攻击
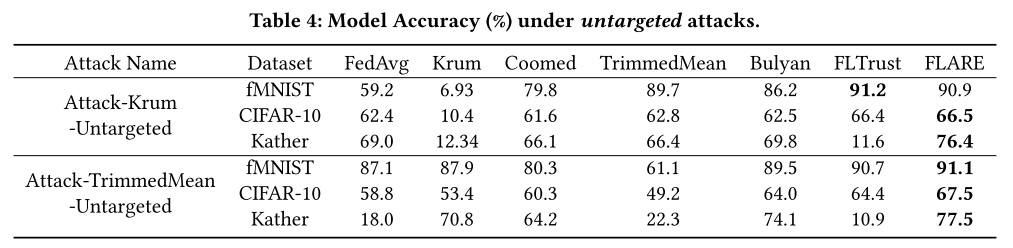
FLARE 通过达到比其他基线高得多的测试精度,成功抵御了非目标 MPA。
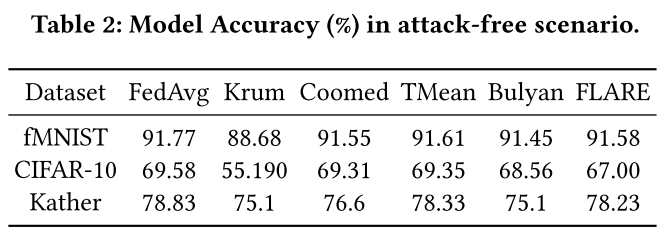
FLARE 的准确性仍然低于无攻击场景(参见表2)。可能的原因与后门 MPA 相同,即缺乏来自恶意更新的有用知识。
- 不同的 FL 设置
客户端数量、攻击者数量、辅助数据点和 Non-I.I.D. 数据
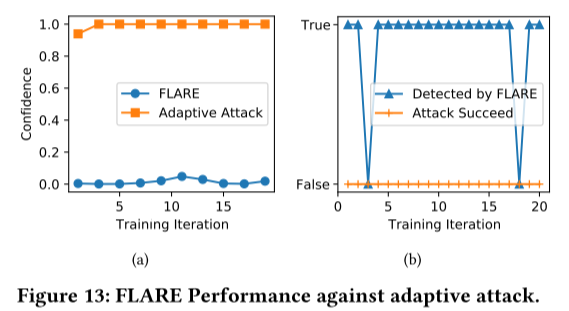
- 自适应攻击
总结
在本文中,我们提出了一种强大的聚合算法 FLARE 来保护 FL 免受 MPAs 的影响。通过分析和实验可视化,我们证明了 PLR 向量在区分恶意/有毒模型和良性模型方面具有很高的潜力。基于 PLR 技术,FLARE 通过将低信任分数分配给具有不同 PLR 的模型,有效地最小化恶意/有毒模型对最终聚合的影响。通过综合评估,我们表明 FLARE 在防御最先进的 MPA(包括语义后门攻击、特洛伊木马攻击和对三个流行数据集的无目标攻击)方面明显优于现有防御措施(即 BRAR 和 FLTrust)。此外,FLARE 在 Non i.i.d. 数据和自适应攻击中也显示出其有效性,展示了对具有挑战性的现实世界场景的适用性。
问题
- 能否使用倒数第三层?
- 实验数据中其他防御的结果为什么会差?FLARE 是否真的有效?
- 服务器必须诚实的?过程有点像推理?